一,动态字符串SDS
我们都知道 Redis 中保存的 Key 是字符串,value 往往是字符串或者字符串的集合。
可见字符串是 Redis 中最常用的一种数据结构,不过 Redis 没有直接使用 C 语言中的字符串,因为 c 语言字符串存在很多问题:
- 获取字符串的长度需要通过运算
- 非二进制安全
- 不可修改
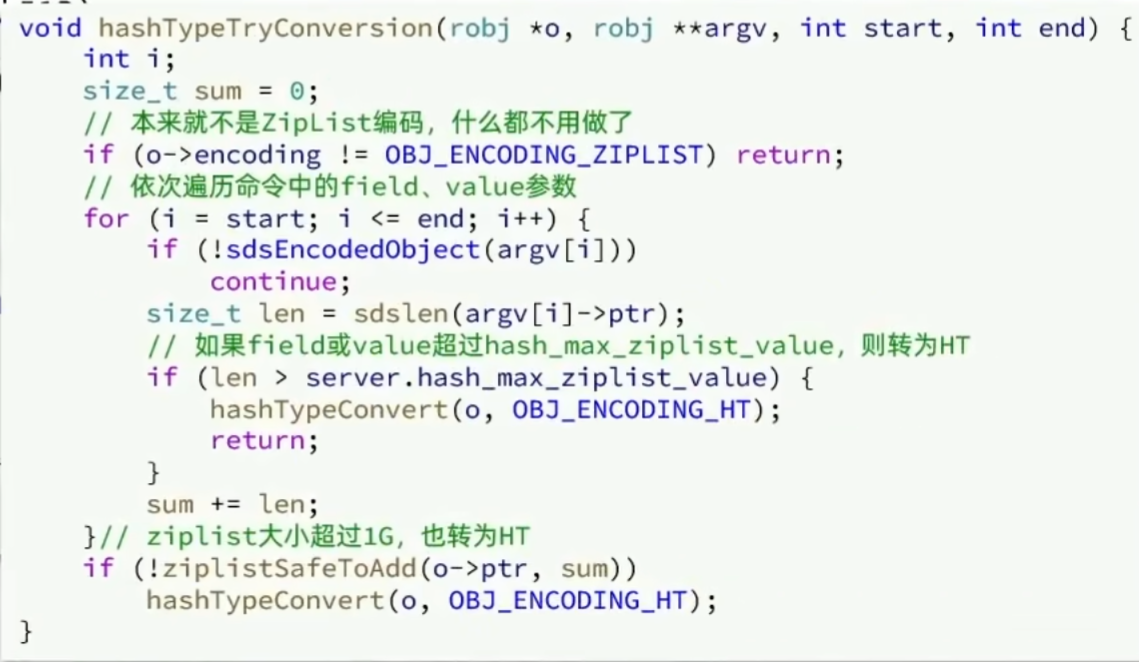
Redis 构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。

Redis 是 C 语言实现的,其中 SDS 是一个结构体,源码如下:

二,IntSet
IntSet是 Redis 中Set 集合的一种实现方式,是基于整数数组来实现的,并且具备长度可变,有序等特征。
结构如下:
typedef struct intset {
uint32_t encoding;/*编码方式,支持存放16位,32位,64位整数*/
uint32_t length;/*元素个数*/
int8_t contents[];/*整数数组,保存集合数据的地址*/
} intset;
其中 encoding 包含三种模式,表示存储的整数大小不同:
#define INTSET_ENC_INT16(sizeof(int16_5))/*2字节整数,范围类似于java的short*/
#define INTSET_ENC_INT32(sizeof(int32_5))/*4字节整数,范围类似于java的int*/
#define INTSET_ENC_INT64(sizeof(int64_5))/*8字节整数,范围类似于java的long*/
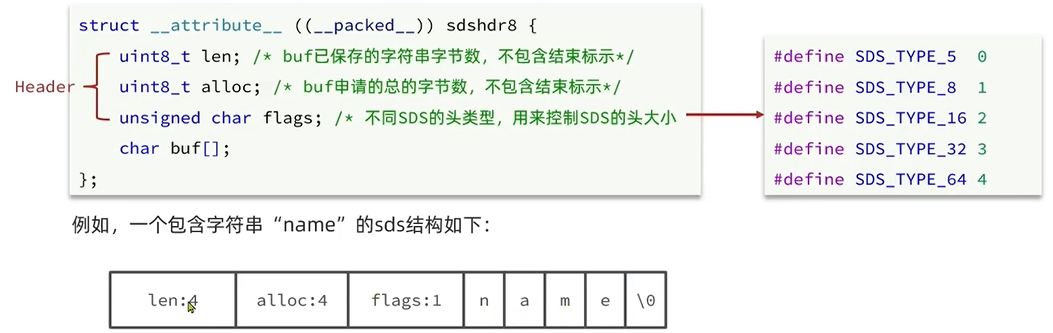
为了方便查找,Redis 会将 intset 中所有的整数按照升序依次保存在 contents 数组中,结构如下:
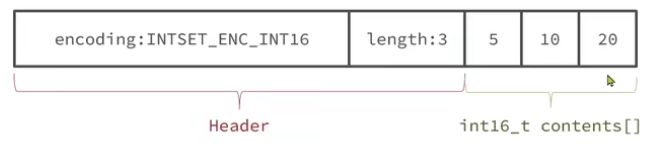
现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4字节
- length:4字节
- contents:2字节*3=6字节
数组元素大小固定的原因是方便寻址,因为 c 语言数组在内存中开辟的是连续的地址,可以通过寻址公式
startPtr + (sizeof(int16) * index)来寻址。
IntSet 升级

IntSet 特点:
- Redis会确保Intset中元素唯一,有序
- 具备类型升级机制,可以节约内存空间
- 底层采用二分查找方式开寻找
三,Dict
我们知道 Redis 是一个键值型 (Key-Value Pair) 的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过 Dict 来实现的。
Dict 由三部分组成,分别是:
- 哈希表(DictHashTable)
- 哈希节点(DictEntry)
- 字段(Dict)

当我们向 Dict 添加键值对时,Redis 首先会根据 key 计算出 hash 值 (h),然后利用 h & sizemask来计算元素应该存储到数组中哪个索引位置。
我们存储 k1=v1,假设 k1 的哈希值 h=1,则1&3=1,因此,k1=v1 要存储到角标 1 位置。
如果此时存储 k2=v2,且计算出角标要存储到 1 位置,则如下:
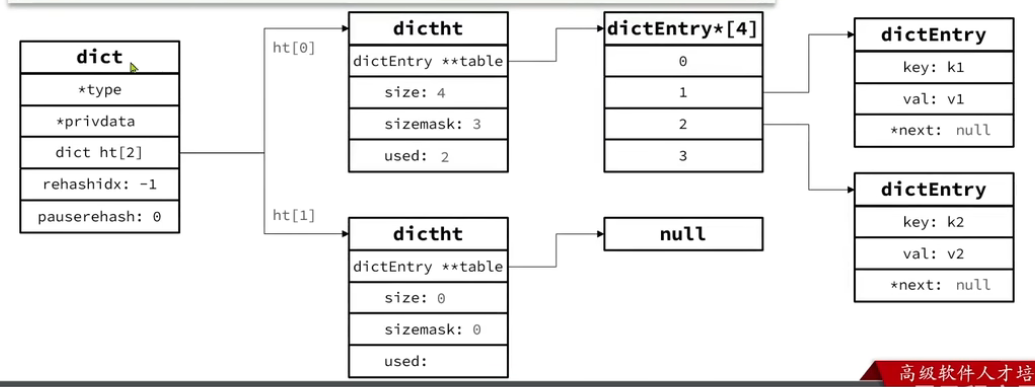
Dict 的扩容:
Dict 中的 HashTable 就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict 在每次新增键值对时都会检查负载因子(LoadFactor=used/size),满足以下两种情况时会触发哈希表扩容
- 哈希表的
LoadFactor>=1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程; - 哈希表的
LoadFactor>5;
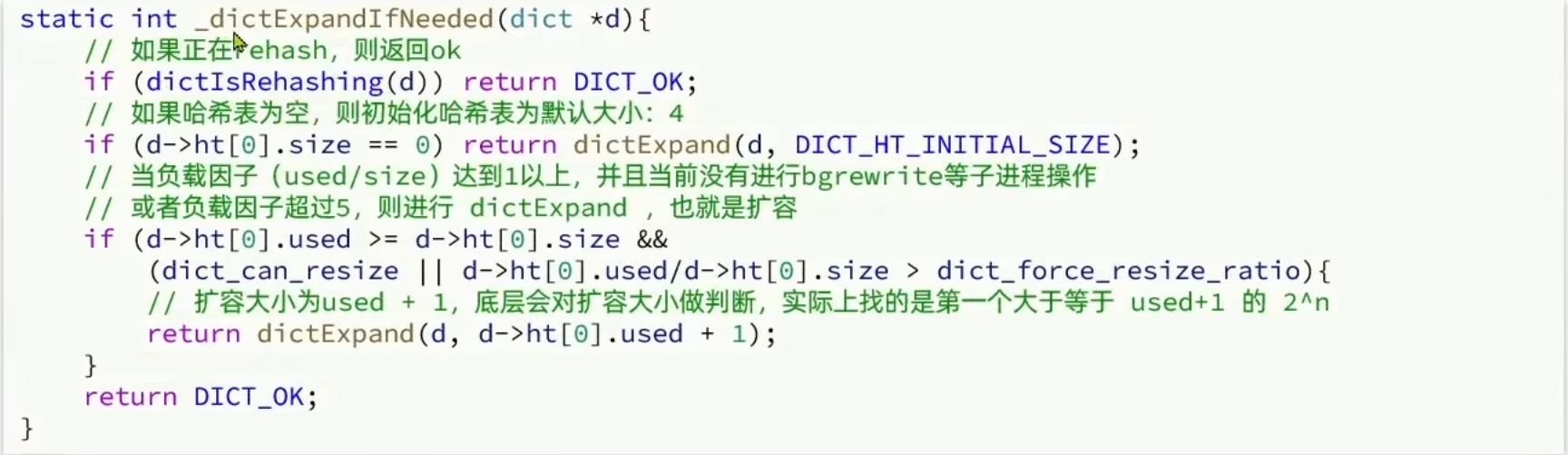
Dict 的收缩
Dict 除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor<0.1时,会做哈希表收缩:
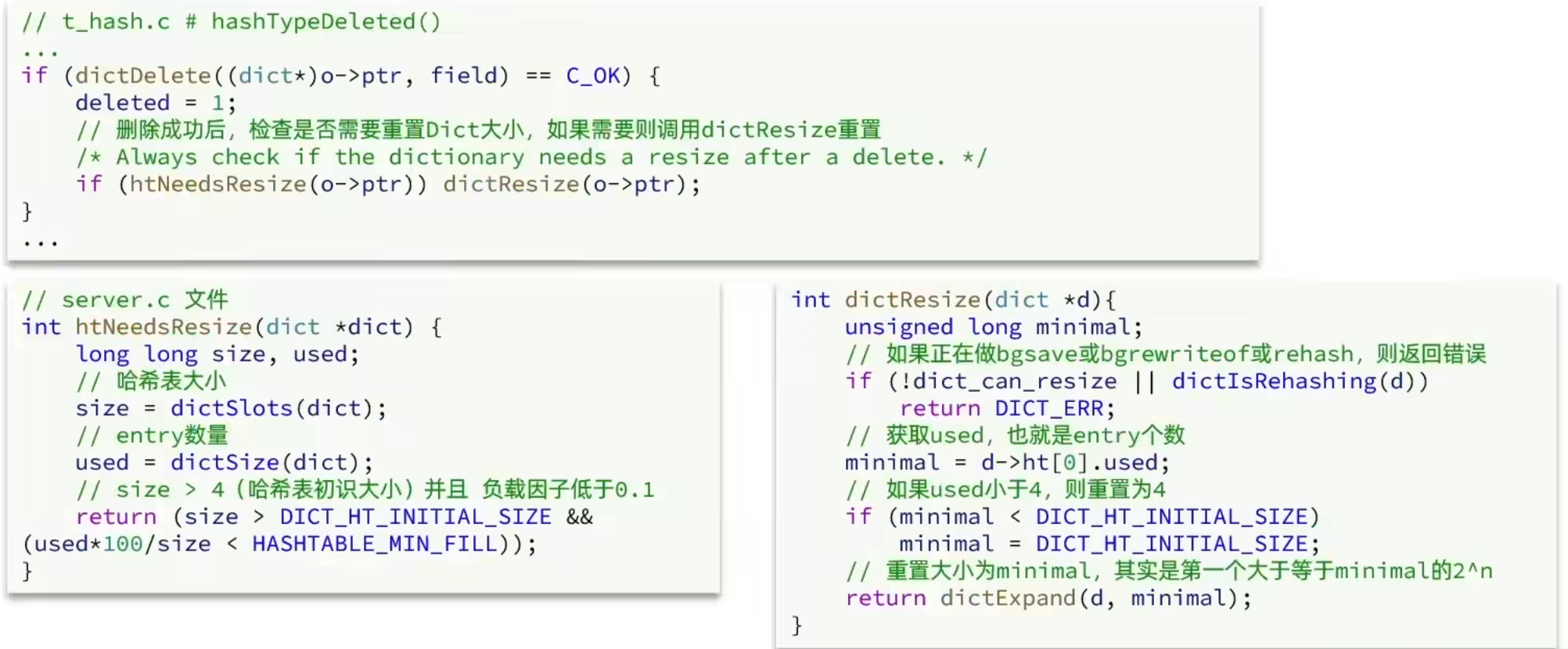
Dict 的 rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key 的查询与 sizemask 有关。因此必须对哈希表中的每一个 key 重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used+1的2n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2n(不小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx=0,标记开始rehash
- 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
Dict 的 rehash 并不是一次性完成的。试想一下,如果 Dict 中包含数百万的 entry,要在一次 rehash 完成,极有可能导致主线程阻寨。因此 Dict 的 rehash 是分多次、渐进式的完成,因此称为渐进式 rehash。流程如下:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used+1的2n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2n(不小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx=0,标记开始rehash
- 每次执行新增,查询,修改,删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并将rehashidx++。直到dict.ht[0]的所有数据都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
- 将rehashidx赋值为-1,代表rehash结束
- 在rehash过程中,新增操作,则直接写入ht[1],查询,修改和删除则会在dict.ht[0]和dict.ht[1]依次查询并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空。
四,ZipList
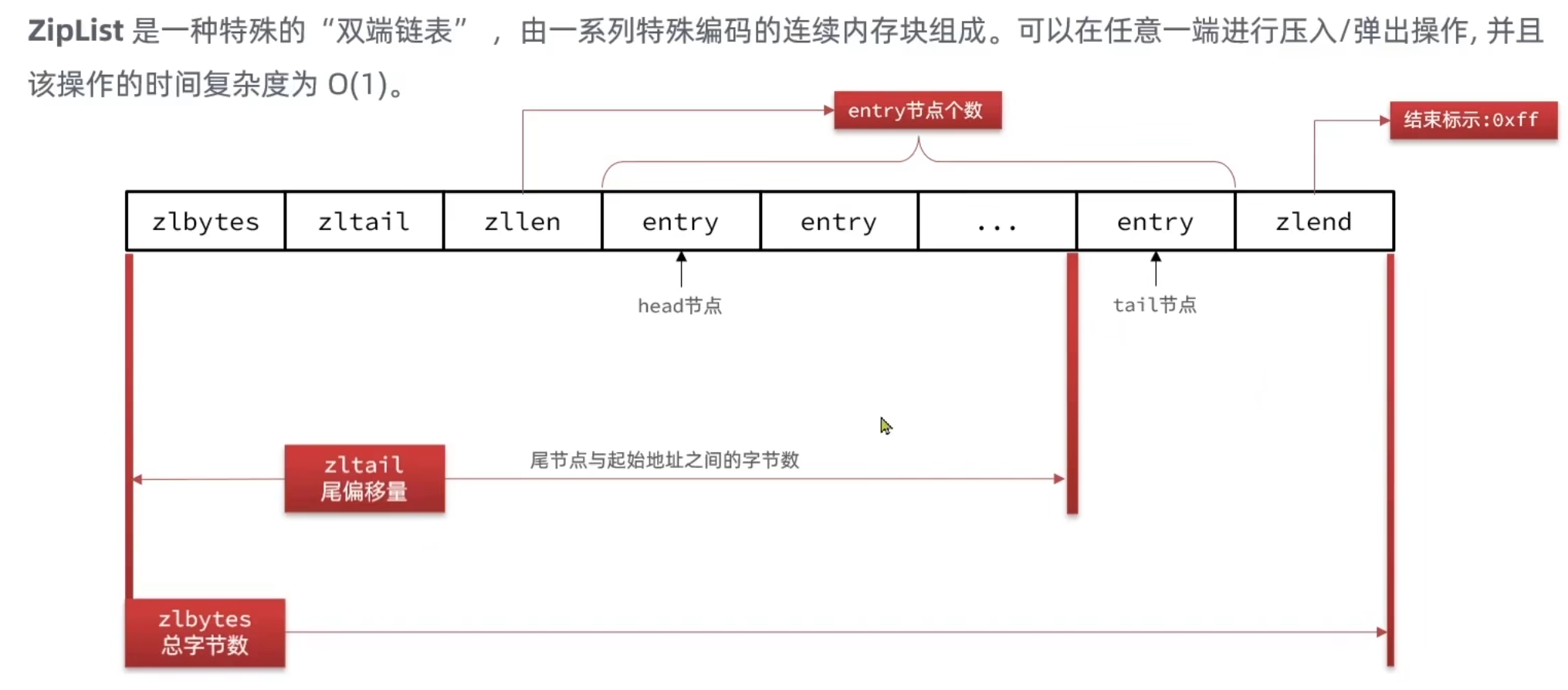
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | unint32_t | 4字节 | 记录整个压缩列表占用内存字节数 |
| zltail | unint32_t | 4字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | unint16_t | 2字节 | 记录了压缩列表包含的节点数量。最大值为UINT16_MAX(65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | unint8_t | 1字节 | 特殊值 0XFF(十进制 255),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的 Entry 并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用 16 个字节,浪费内存。而是采用了下面的结构:

- previous_entry_length:前一节点的长度,占1个或5个字节
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值。
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后续四个字节才是真实长度数据
- encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个,2个或者5个字节
- contents:负责保存节点的数据,可以是字符串或者整数
注意:ZipList 中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值 0x1234,采用小端字节序后实际存储值为:0x3412
Encoding 编码
ZipListEntry 中的 encoding 编码分为字符串和整数两种:
-
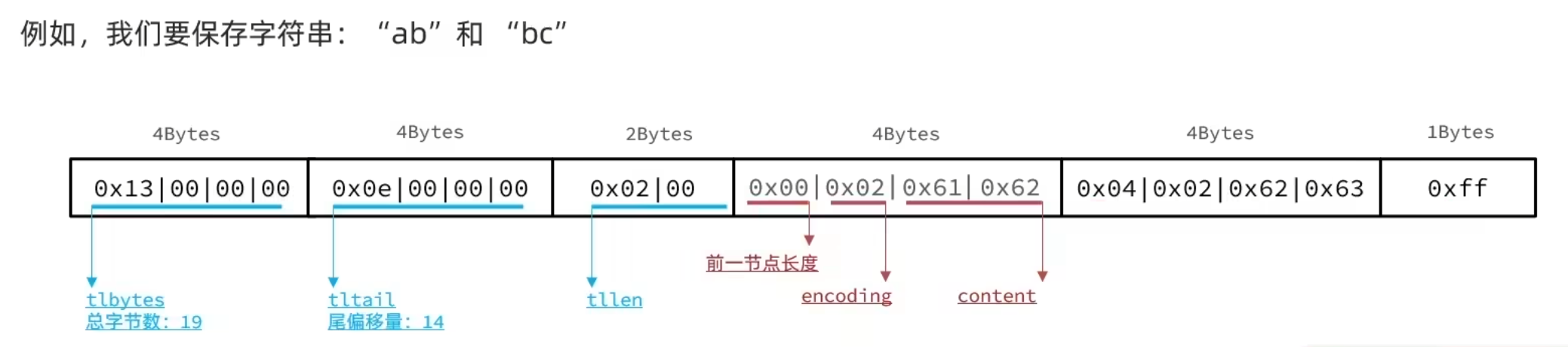
字符串:如果 encoding 是以:00,01 或者 10 开头,则证明 content 是字符串
编码 编码长度 字符串大小 |00pppppp| 1 bytes <= 63bytes |01pppppp|qqqqqqqq| 2 bytes <= 16383 bytes |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| 5 bytes <= 4294967295 bytes
-
整数:如果encoding是以 11 开始,则证明 content 是整数,且 encoding 固定只占用 1 个字节
编码 编码长度 整数类型 11000000 1 int_16_t(2 bytes) 11010000 1 int_32_t(2 bytes) 11100000 1 int_64_t(2 bytes) 11110000 1 24位有符整数(3 bytes) 11111110 1 8位有符整数(1 bytes) 1111xxxx 1 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值
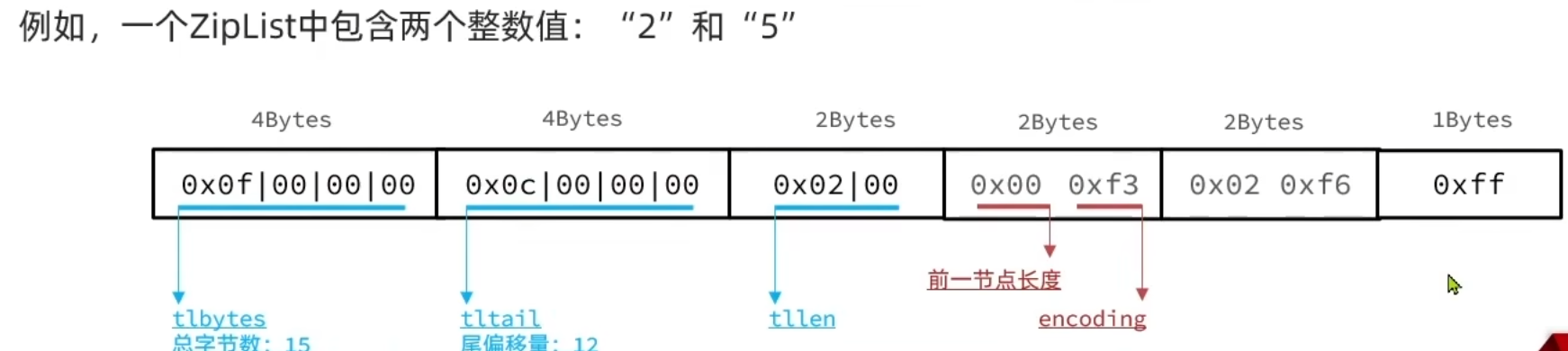
ZipList 的连锁更新问题
ZipList 的每个 Entry 都包含previous_entry_length来记录上一个节点的大小,长度是 1 个或者 5 个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值。
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后续四个字节才是真实长度数据
现在,假设我们有 N 个连续的、长度为 250~253 字节之间的 entry,因此 entry 的 previous entry length 属性用 1 个字节即可表示,如图所示:

此时,插入一个长度为 254byte 的 entry 到队首,此时所有的 previous_entry_length 会连锁更新,从 1bytes 变成 5bytes

ZipList 这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新。新增,删除都可能导致连锁更新的发送。
ZipList 特性
- 压缩列表的可以看做一种连续内存空间的"双向链表
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
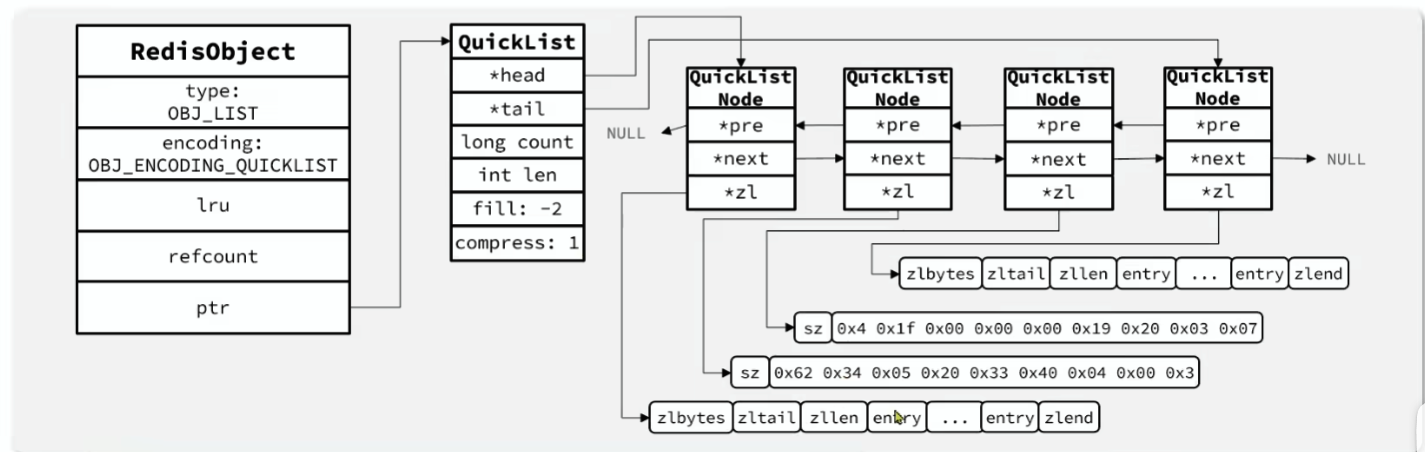
五,QuickList
问题 1:ZipList 虽然节省内存空间,但申请内存必须是连续空间,如果内存占用较多,申请效率就很低。
- 为了缓解这个问题,我们必须限制ZipList的长度和Entry大小
问题 2:但是我们要存储大量数据,超出了 ZipList 最佳上限怎么办?
- 我们可以创建多个ZipList来分片存储数据
问题 3:数据拆分后比较分散,不方便查找和管理,者多个 ZipList 如何建立联系?
- Redis在3.2版本以后引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList
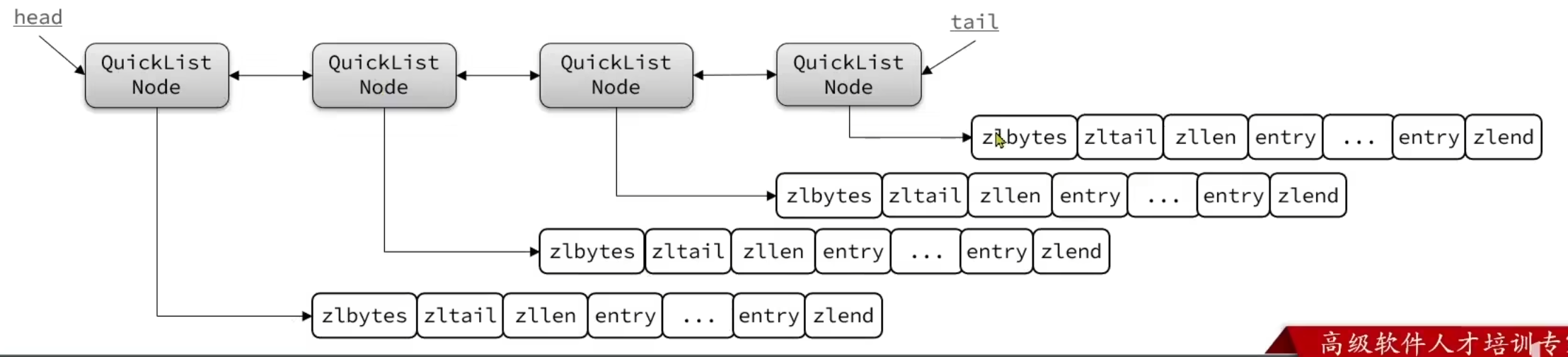
为了避免 QuickList 中的每个 ZipList 中的 entry 过多,Redis 提供了一个配置项:list-max-ziplist-size来限制:
- 如果值为正,则代表ZipList的允许entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
-1:每个ZipList的内存占用不超过4kb-2:每个ZipList的内存占用不超过8kb(默认值)-3:每个ZipList的内存占用不超过16kb-4:每个ZipList的内存占用不超过32kb-5:每个ZipList的内存占用不超过64kb
除了控制 ZipList 的大小,QuickList 还可以对节点的 ZipList 做压缩。通过配置项list-compress-depth来控制。因为链表一般都是从首尾访问较多,所以首尾是不压缩的。这个参数是控制首尾不压缩的节点个数:
0:特殊值,代表不压缩(默认值)1:表示QuickList的首尾各有1个节点不压缩,中间节点压缩2:表示QuickList的首尾各有2个节点不压缩,中间节点压缩- 以此类推

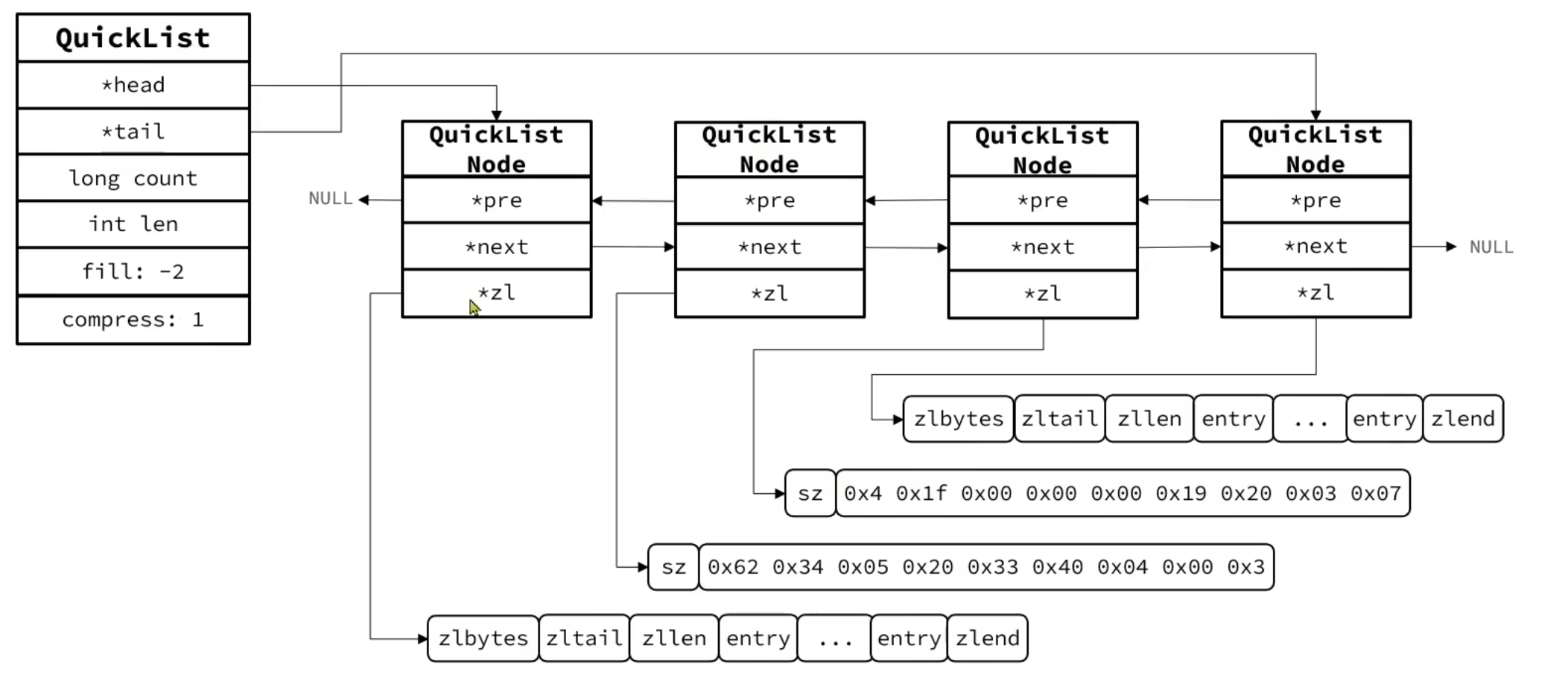
QuickList 的特点
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小**,解决连续内存空间申请效率问题**
- 中间节点可以压缩,进一步节省了内存
六,SkipList
SkipList(跳表) 首先是链表,但与传统链表有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
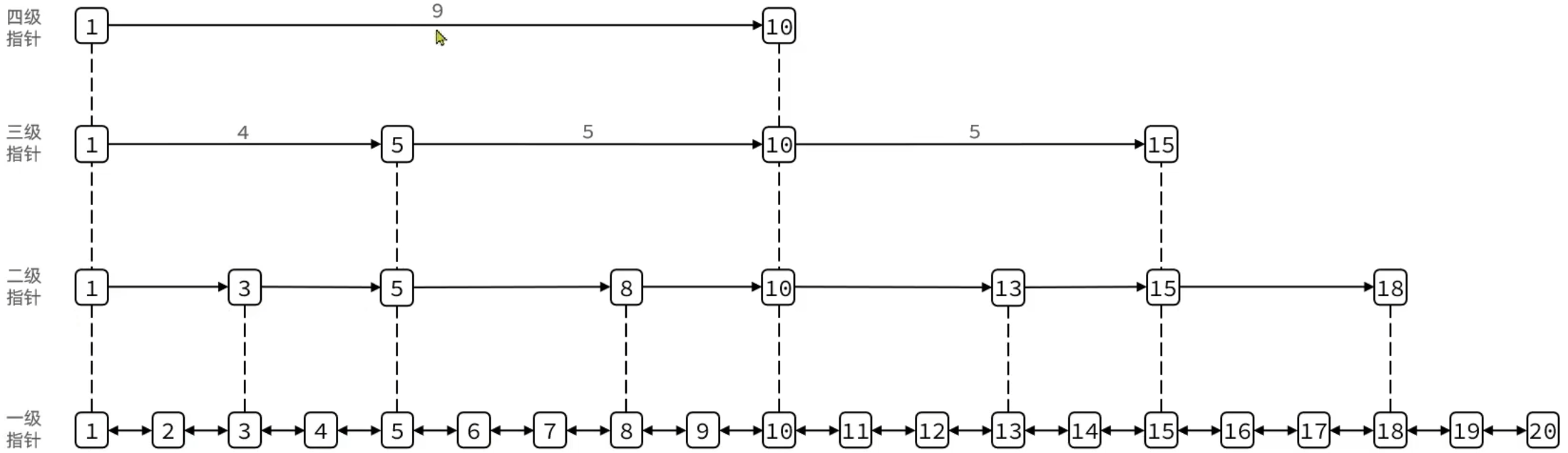

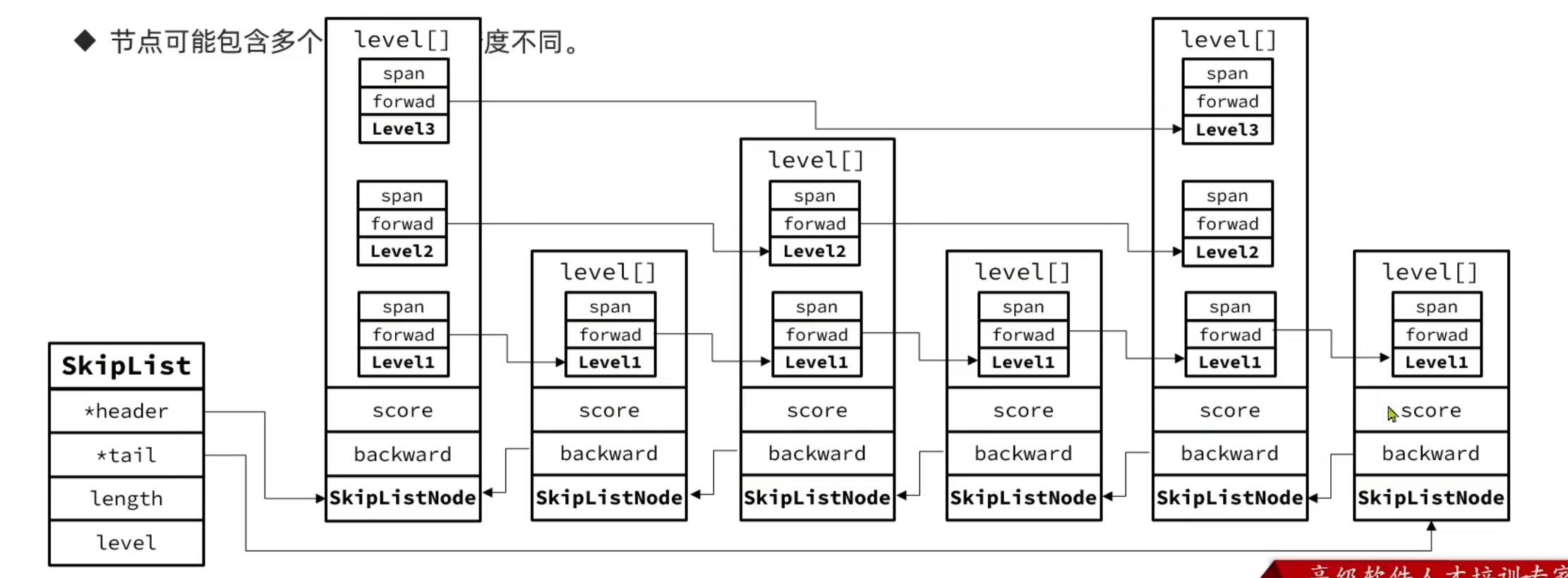
SkipList 的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
七,RedisObject
Redis 中的任意数据类型的键和值都会被封装为一个 RedisObject,也叫做 Redis 对象,源码如下:
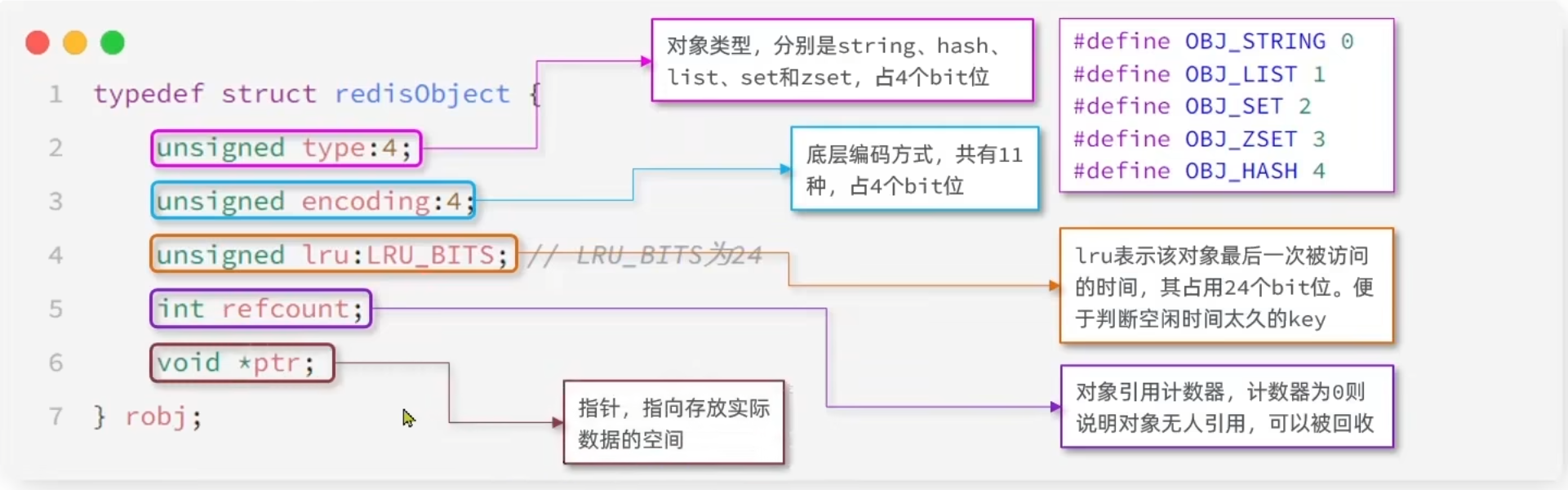
可以看到整个结构体中并不包含真实的数据,仅仅是对象头信息,内存占用的大小为 4+4+24+32+64 = 128bit
也就是 16 字节,然后指针ptr指针指向的才是真实数据存储的内存地址。所以 RedisObject 的内存开销是很大的。
Redis 中会根据存储的数据类型不同,选择不同的编码方式,共包含 11 种不同类型
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
Redis 中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
八,五种常见的数据结构
8.1 String
String 是 Redis 中最常见的数据存储类型:
-
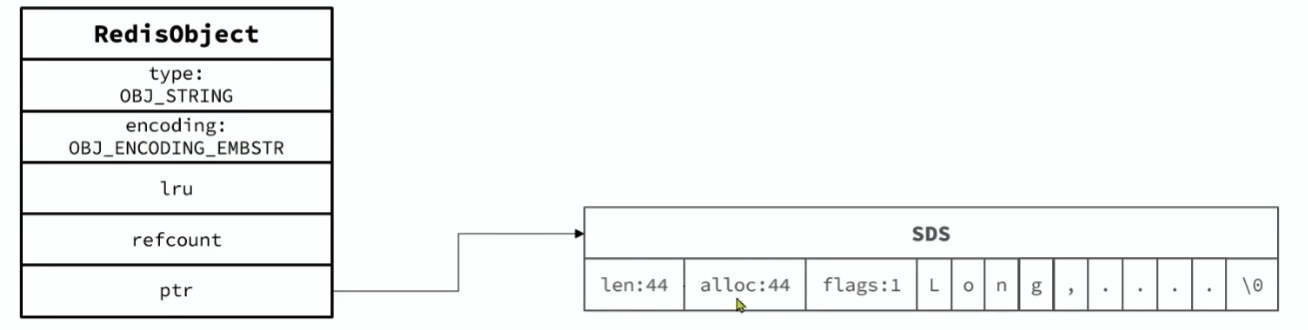
其基本编码方式是RAW,基于简单动态字符串 SDS 实现,存储上限为 512MB
-
如果存储的 SDS 长度小于 44 字节,则会采用EMBSTR编码,此时 object head 与 SDS 是一 ** 段连续空间。** 申请内存时只需要调用一次内存分配函数,效率更高。
-
如果存储的字符串是整数值,并且大小在 LONG_MAX 范围内,则会采用INT编码;直接将数据保存在 RedisObject 的 ptr 指针位置(刚好 8 字节),此时不需要 SDS 了。
-
RAW 编码的 String
-
embstr 编码的 String

-
int 编码的 String

-
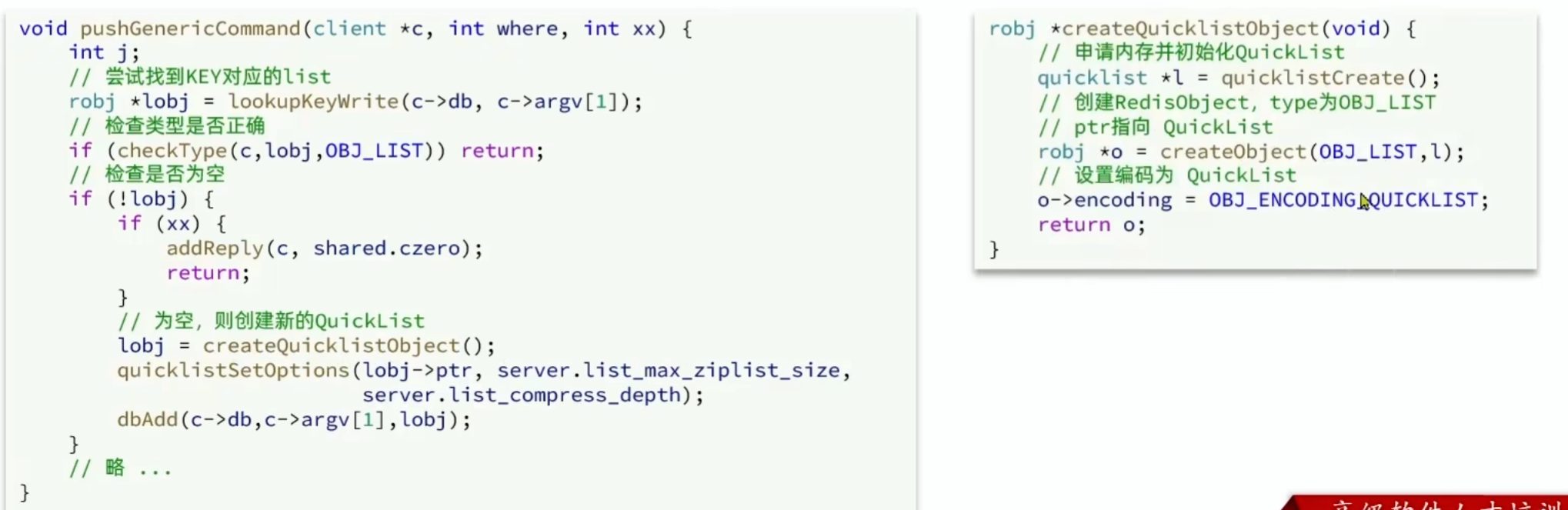
8.2 List
Redis 的 List 类型可以从首、位操作列表中的元素
满足上述特征的数据结构:
-
LinkedList:普通链表,可以从双端访问,内存占用较高。
-
ZipList:压缩列表,可以从双端访问,内存占用较低,存储上限低。
-
QuickList:LinkedList+ZipList,可以从双端访问,内存占用较低,包含多个 ZipList,存储上限高。
Redis 的 List 结构类似一个双端链表,可以从首、尾操作列表中的元素:
- 在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
- 在3.2版本之后,Redis统一采用QuickList来实现List
8.3 Set
Set 是 Redis 中的单列集合,满足下列特点:
- 不保证有序性
- 保证元素唯一(可判断元素是否存在)
- 求交集、并集、差集
可以看出,Set 对查询元素的效率要求非常高,满足它的数据结构有:
- HashTable,也就是Redis中的Dict,不过Dict是双列集合。
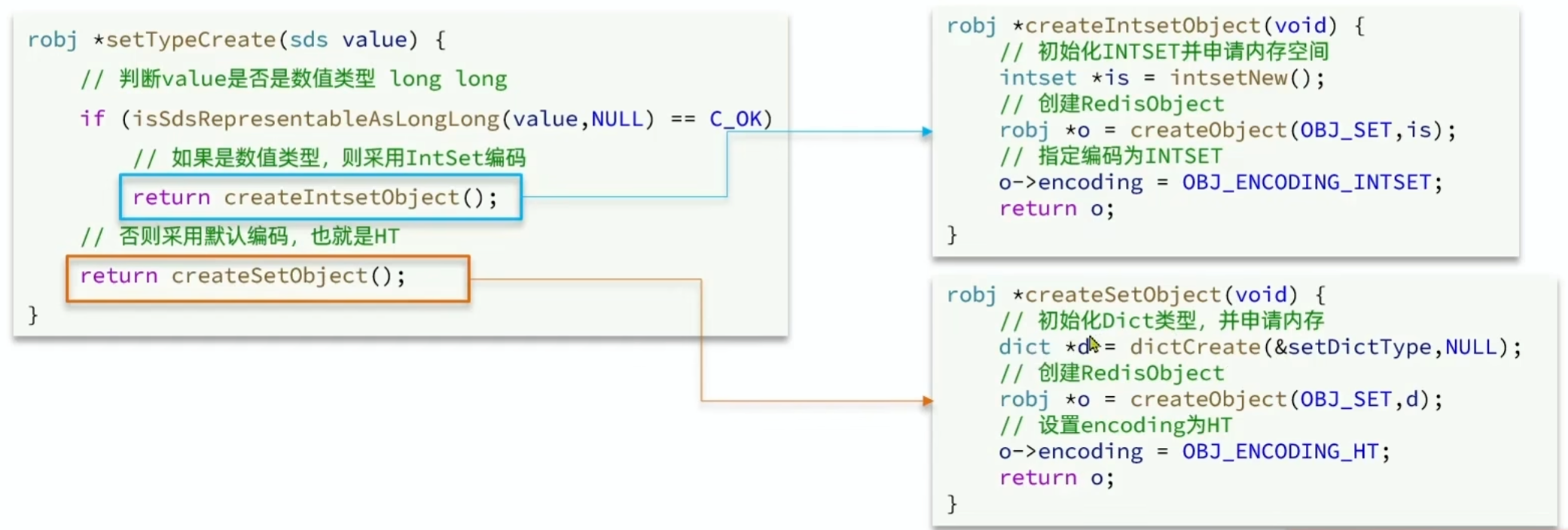
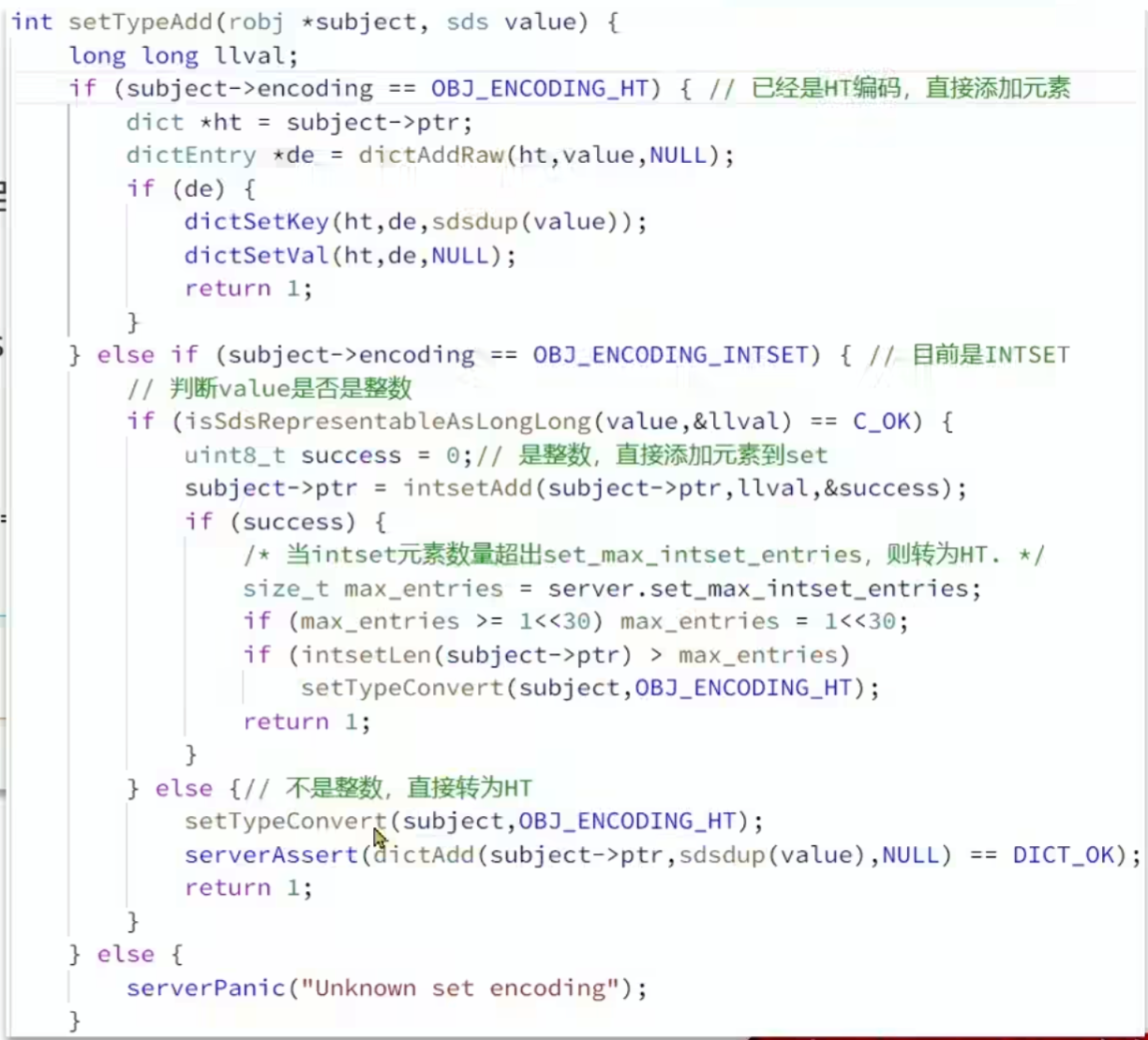
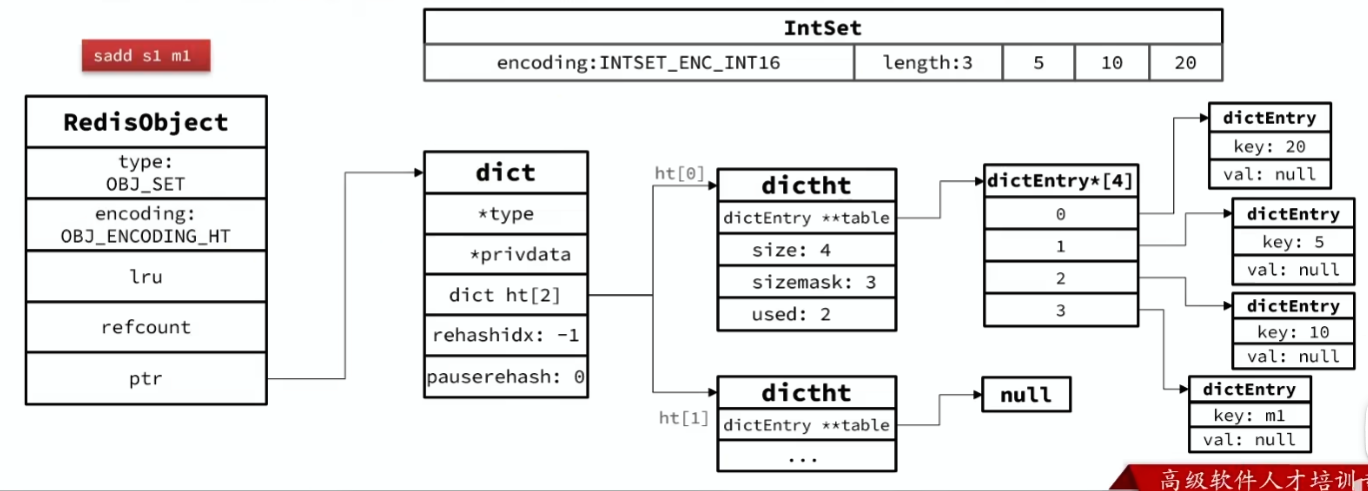
- 为了查询效率和唯一性,Set采用HT编码(Dict)Dict中的key用来存储元素,value统一为null
- 当存储的所以数据都是整数,并且元素数量不超过
set-max-intset-entries时,Set会采用IntSet编码,以节省内存。 set-max-intset-entries默认值为512
编码转化内存图:
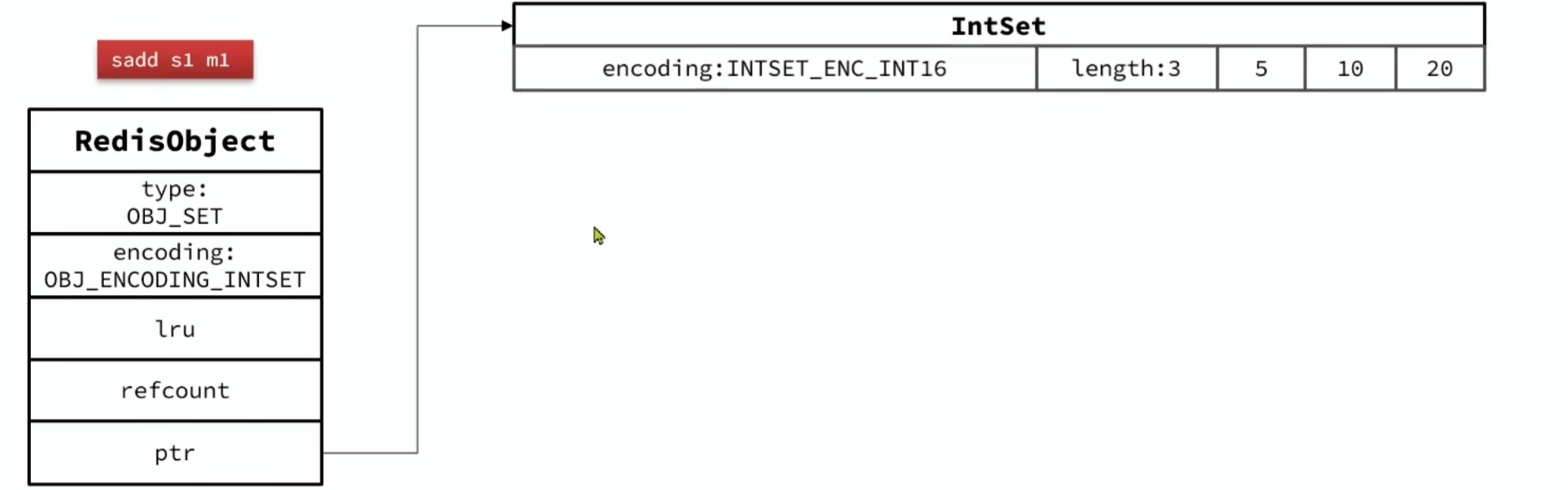
-
初始为 IntSet 时:
-
转化为 ht 时
8.4 ZSet
ZSet 也就是 SortedSet,其中每一个元素都需要指定一个score 值和 member 值
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数
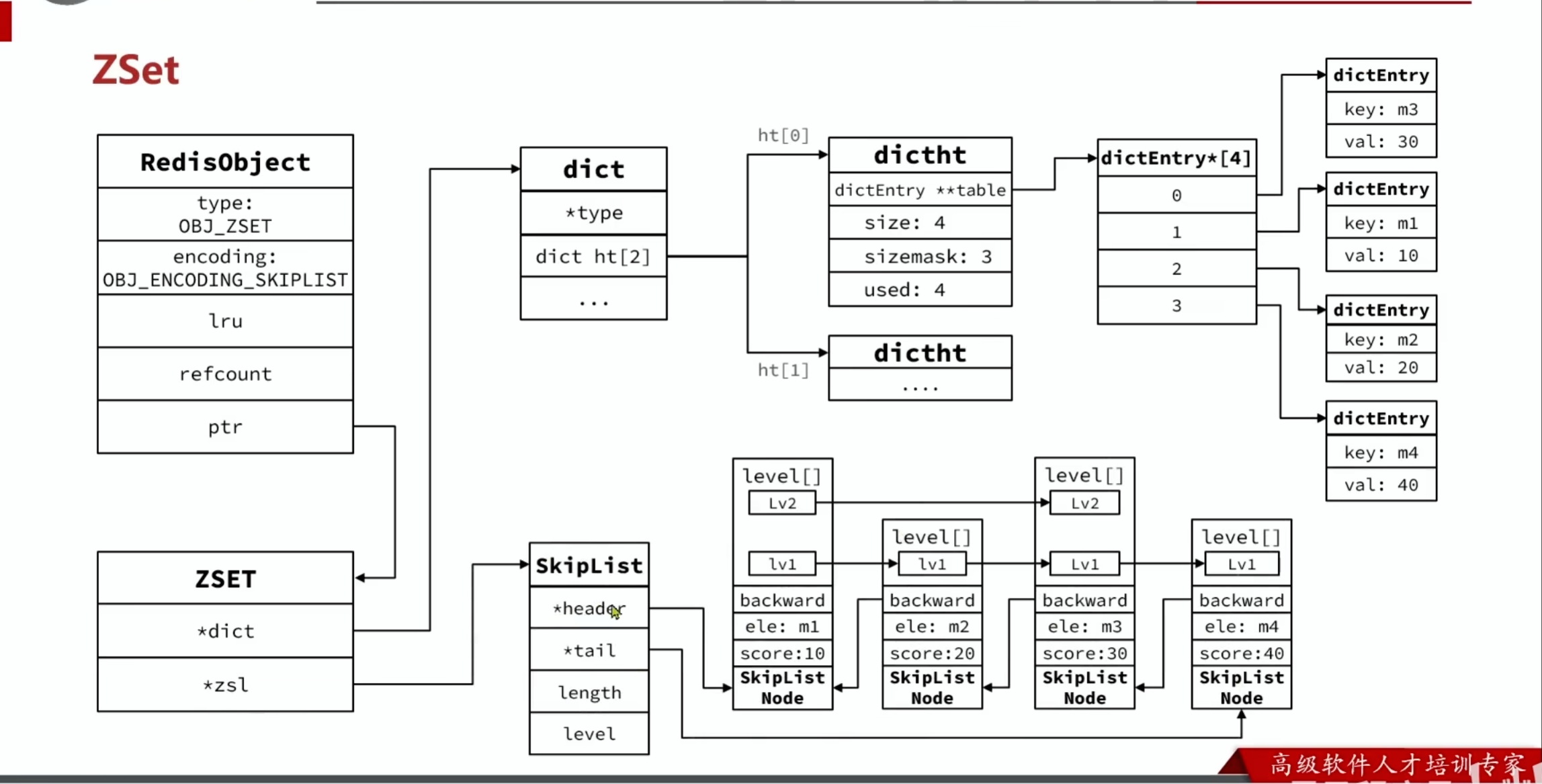
因此,zset 底层数据结构必须满足键值存储,健必须唯一,可排序这几个特点。
- SkipList:可排序,并且可同时存储score和ele值(member),但是不能实现高效的健值唯一性检查
- HT(Dict):可以键值存储,并且可以根据key找到value,但是不能排序
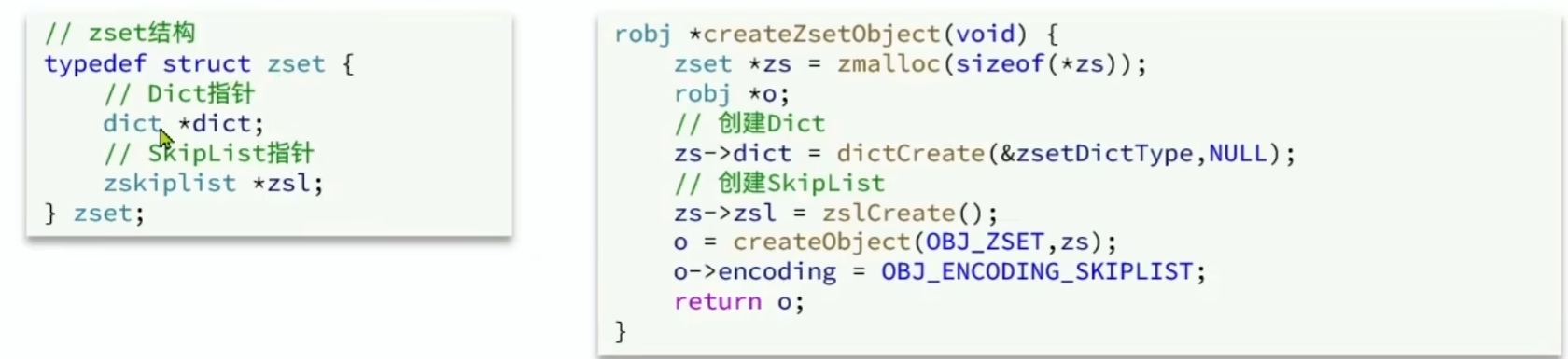
Redis 通过结合两个数据结构,来实现 ZSet
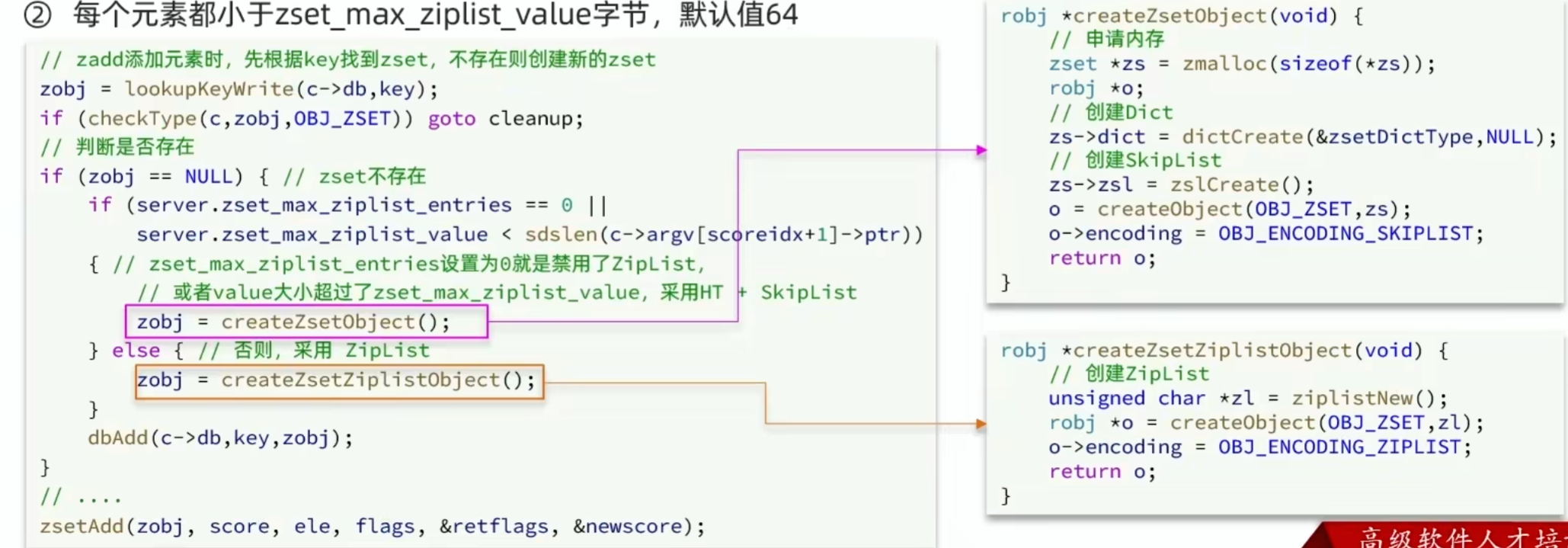
当元素数量不多时,HT 和 SkipList 的优势不明显,而且更耗内存。因此 zset 还会采用 ZipList 结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于
zset_max_ziplist_entires,默认值128 - 每个元素都小于
zset_max_ziplist_value字节,默认64
ZipList 转化 HT+SkipList

ZipList 本身没有排序功能,而且没有键值对概念,因此需要有 zset 通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry,element在前score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排序
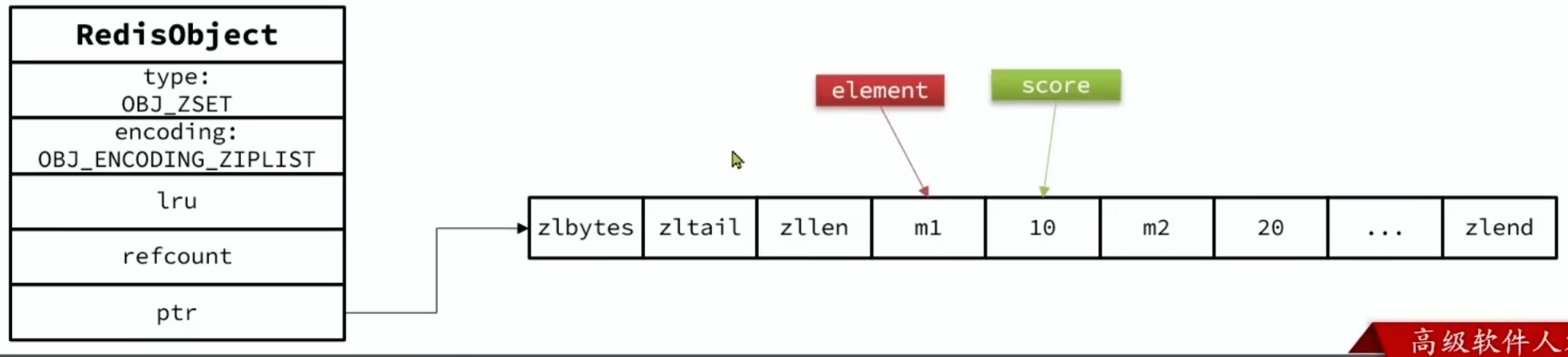
面试题:Redis 的SortedSet底层的数据结构是怎样的?
答:SortedSet 是有序集合,底层的存储的每个数据都包含element和score两个值。score 是得分,element 则是字符串值。SortedSet 会根据每个 element 的 score 值排序,形成有序集合。
它支持的操作很多,比如:
- 根据element查询score值
- 按照score值升序或降序查询element
要实现根据 element 查询对应的 score 值,就必须实现 element 与 score 之间的键值映射。SortedSet 底层是基于HashTable来实现的。
要实现对 score 值排序,并且查询效率还高,就需要有一种高效的有序数据结构,SortedSet 是基于跳表实现的。
加分项:因为 SortedSet 底层需要用到两种数据结构,对内存占用比较高。因此 Redis 底层会对 SortedSet 中的元素大小做判断。如果元素大小小于 128且每个元素都小于 64 字节,SortedSet 底层会采用ZipList,也就是压缩列表来代替HashTable和SkipList
不过,ZipList存在连锁更新问题,因此而在 Redis7.0 版本以后,ZipList又被替换为Listpack(紧凑列表)。
8.5 Hash
Hash 结构与 Redis 中的 Zset 非常类似:
- 都是键值对存储
- 都需求根据健获取值
- 健必须唯一
区别如下:
- zset的健是member,值是score;hash的健和值都是任意值
- zset要根据score排序;hash则无需排序
因此,Hash 底层采用的编码与 Zset 也基本一致,只需要把排序有关的 SkipList 去掉即可。
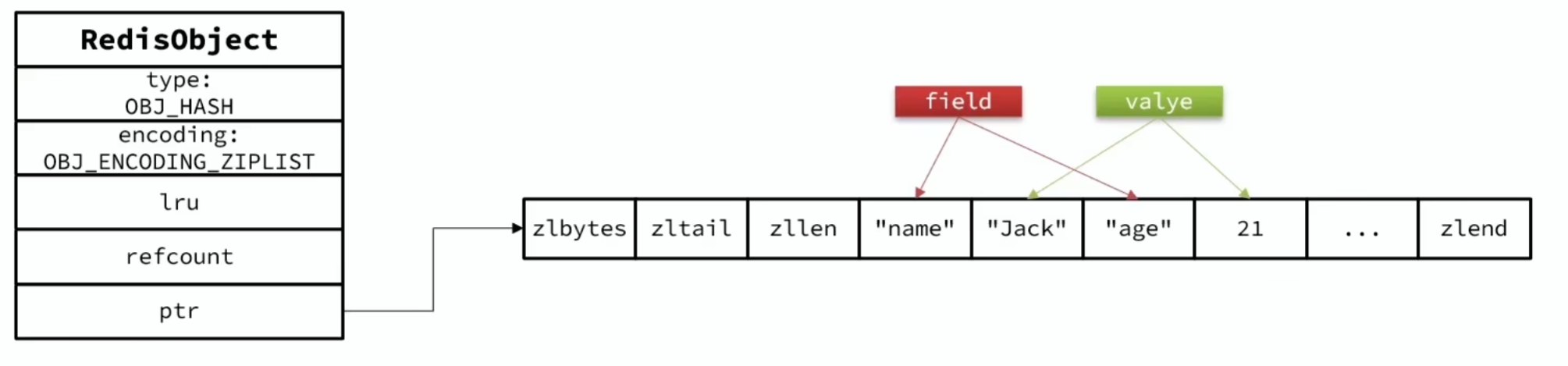
-
Hash 结构默认采用ZipList编码,用以节省内存。ZipList 中相邻的两个 entry 分别保存 field 和 value
-
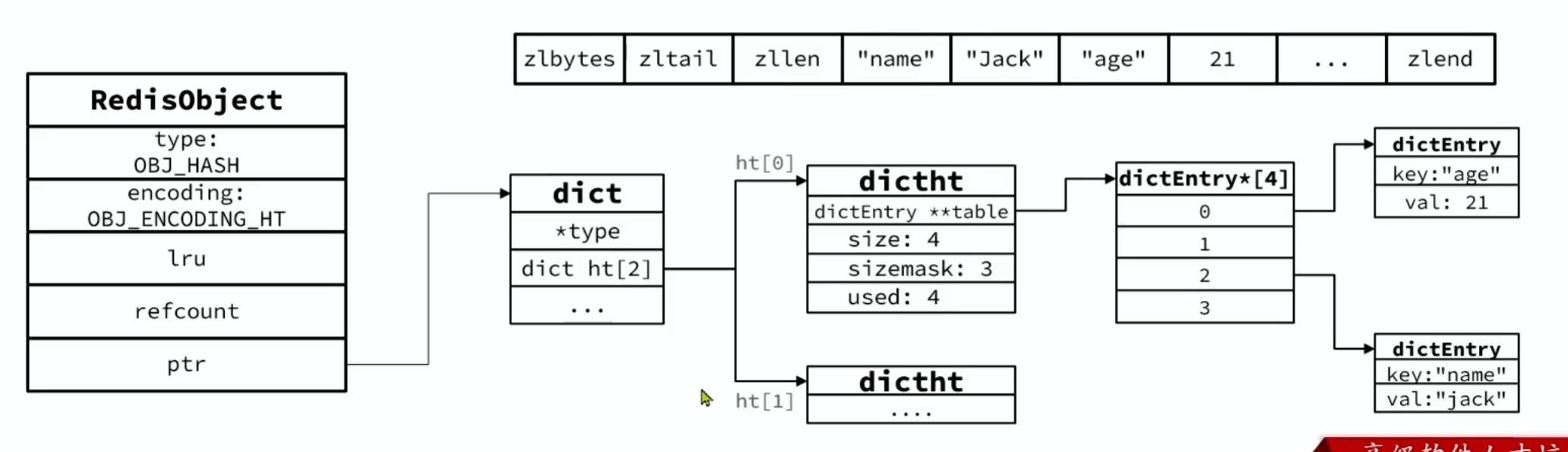
当数据量较大时,Hash 结构会转为HT 编码,也就是 Dict,触发条件为:
- ZipList中的元素数量超过了
hash-max-ziplist-entires默认512 - ZipList中的任意entry大小超过了
hash-max-ziplist-value默认64字节
- ZipList中的元素数量超过了
源码片段