

一,Insert优化
1.1 SQL语句优化
-
批量插入(Bulk Insert)
INSERT INTO table (col1, col2) VALUES (v1, v2), (v3, v4), ...;- 单次插入多条数据(建议500~2000条/批)
- 减少网络传输和SQL解析开销
-
LOAD DATA INFILE
LOAD DATA INFILE '/path/data.csv' INTO TABLE table;- 比普通INSERT快20倍以上
- 绕过SQL解析层直接导入
-
禁用自动提交
START TRANSACTION; INSERT...; INSERT...; COMMIT;- 将多个INSERT包裹在事务中
- 减少磁盘刷写次数
1.2 存储引擎调优
InnoDB 优化:
-
配置参数调整:
innodb_buffer_pool_size = 系统内存的70-80% innodb_flush_log_at_trx_commit = 2 # 批量刷盘 innodb_log_file_size = 4G # 更大的redo日志 innodb_autoinc_lock_mode = 2 # 交错自增锁模式 -
页压缩:
CREATE TABLE ... ROW_FORMAT=COMPRESSED;
MyISAM 适用场景:
-
只用于插入密集型、非事务需求场景
-
配置调整:
concurrent_insert = 2 # 允许并发插入 bulk_insert_buffer_size = 256M
二,主键优化
2.1 索引组织表(IOT)
在 innodb 引擎中表数据是根据主键顺序存放的。这种存储关系叫索引组织表 (IOT)
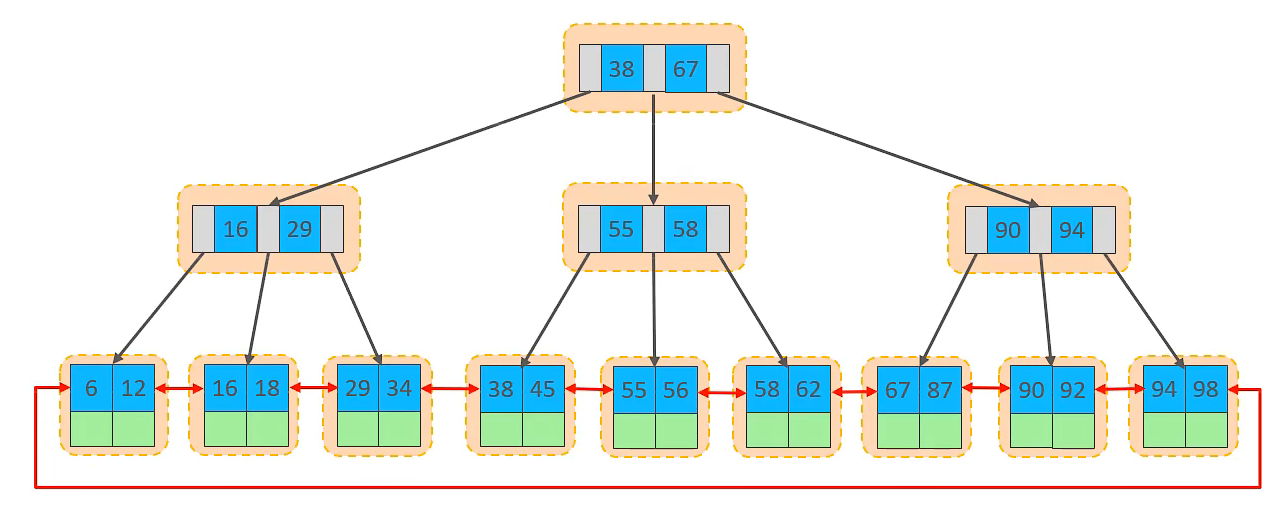
如上图,就是以主键顺序存放的索引组织表。
- 叶子节点存放数据,非叶子节点起到索引的作用。
- 这些黄色的块全部是由逻辑层次结构页(page)组成的。
- 页是innodb磁盘管理的最小单元,最大16k
- 页内数据根据主键顺序插入
2.2 页分裂
页可以为空,可以存一半,可以充满,每一个页知识包含 2 行数据,如果某一行数据过大会产生行溢出现象。
2.2.1 主键顺序插入的流程图
-
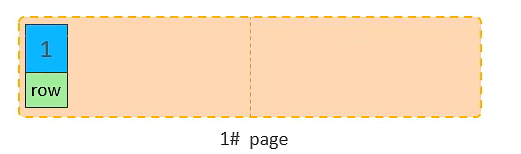
插入 id=1 的数据
-
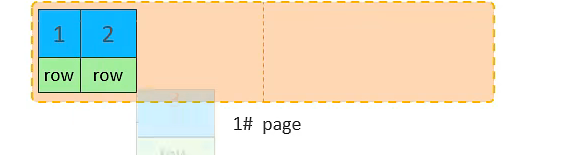
插入 id=2 的数据
-
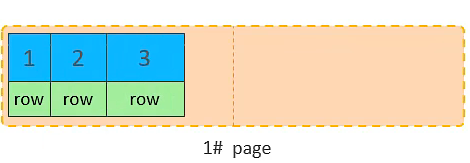
插入 id=3 的数据
-
插入 id=4 的数据
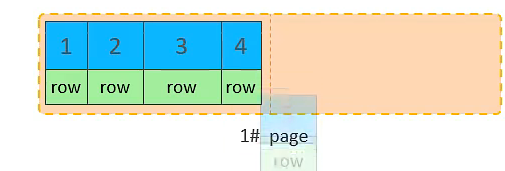
-
插入 id=5 的数据
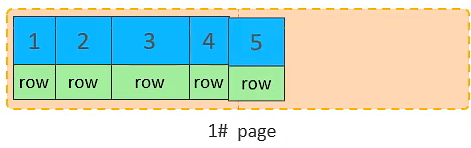
-
插入 id=6 的数据
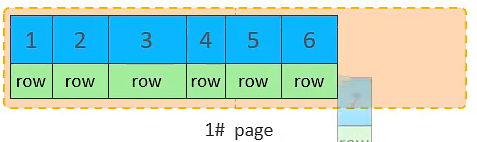
-
插入 id=7 的数据
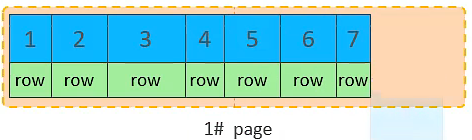
-
插入 id=8 的数据
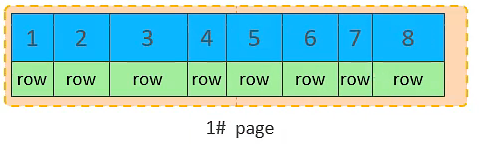
-
当第一个数据页写满后,想插入 9 就先申请第二个页并插入 9, 且将他们之间维护一个双向指针!

-
将第二页写满

2.2.2 主键乱序插入的流程图
-
假定已经存放如下数据

-
这时我们想插入一条 id=50 的数据, 本应该插入到 47 和 55 之间,但是他们已经满了。
故先开辟新的数据页 3,因为在第一页中 23 和 47 占了页的一半,故移动 23 和 47 到新的页 3 去,然后将 50 插入到 47 后

-
最后重构链表指针

2.3 页合并
假定当前叶子节点的情况如图

当删除一行记录时,实际上并没有被物理删除,只是被标记为删除并且他的空间变得运行其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的 50%),InnoDB 会开始寻找最靠近的页 (前或后) 看看是否可以将俩个页合并从而优化空间使用。
最终会变成如图

MERGE_THRESHOLD 页合并参数的阈值,可以自己设置,在创建表或者索引的时候指定即可。
MERGE_THRESHOLD 参数设置过程
-
创建表的时候设置
create table 表名( 字段1 类型, ... 字段n 类型 )comment='MERGE_THRESHOLD=45'; -
修改
ALTER TABLE t1 COMMENT='MERGE_THRESHOLD=40';
2.4 主键设计原则
-
尽量降低主键的长度
理由:在聚集索引和二级索引中,如果二级索引很多并且,主键索引很长那么会占用很大的空间,搜索的时候会降低大量的磁盘 io。
-
插入数据的时候尽量使用顺序插入,auto_increment 约束
理由: 如果乱序插入会可能出现页分裂现象
-
业务操作的时候避免对主键的修改
三,Order by优化
explain 中的extra会出现 2 种情况在 order by 中
-
using filesort
通过表的扫描或者索引,读取满足条件的数据行,然后在排序缓冲区 (sort buffer) 中完成排序操作,所有不是通过索引直接返回排序结构的叫
using filesort,需要查出来后额外排序,效率低。 -
using index
通过有序索引顺序扫描直接返回有序结构,不需要额外排序操作,效率高。
将 using filesort 优化成 using index 的办法:在创建索引的时候规定排序方式
create index 索引名 on 表名(字段1 排序方式,字段2 排序方式...);
注意要点: 记得遵循索引规则
- 如果无法避免必须使用using filesort,可以增加
sort_buffer_size区的大小(默认256kb)
查询 sort_buffer_size 的大小
show variables like 'sort_buffer_size';
设置 sort_buffer_size 的大小
set global sort_buffer_size=大小;
四,Group by优化
explain 中的 extra 会出现一种情况说明 group by 的效率较低
-
using tempory:代表 MYSQL 使用了临时表 -
解决办法: 给分组的字段加上索引优化。
五,Limit优化
5.1 基础优化原则
-
避免全表扫描
-- 低效写法(扫描前100010行) SELECT * FROM orders ORDER BY id LIMIT 100000, 10; -- 优化方案:使用覆盖索引 SELECT * FROM orders WHERE id > 100000 ORDER BY id LIMIT 10; -
游标分页(Cursor-based Pagination)
-- 传统分页(性能差) SELECT * FROM products ORDER BY created_at DESC LIMIT 10000, 20; -- 游标分页(记住最后一条的created_at和id) SELECT * FROM products WHERE created_at < '2023-08-01 12:00:00' AND id < 5000 ORDER BY created_at DESC, id DESC LIMIT 20;
5.2 高级优化技巧
-
延迟关联(Deferred Join)
-- 原始查询(全表扫描) SELECT * FROM users WHERE country='CN' ORDER BY score DESC LIMIT 100000, 10; -- 优化版本(先查主键) SELECT users.* FROM users JOIN ( SELECT id FROM users WHERE country='CN' ORDER BY score DESC LIMIT 100000, 10 ) AS tmp USING(id); -
预计算分页数据
-- 创建分页元数据表 CREATE TABLE page_metadata ( page_num INT, start_id INT, end_id INT, PRIMARY KEY (page_num) ); -- 定期预计算(每页100条) REPLACE INTO page_metadata SELECT (ROW_NUMBER() OVER (ORDER BY id)-1)/100 +1 AS page_num, MIN(id) AS start_id, MAX(id) AS end_id FROM orders GROUP BY (ROW_NUMBER() OVER (ORDER BY id)-1)/100; -- 使用元数据快速分页 SELECT * FROM orders WHERE id BETWEEN (SELECT start_id FROM page_metadata WHERE page_num=1000) AND (SELECT end_id FROM page_metadata WHERE page_num=1000);
六,Count优化
在 InnoDB 存储引擎中他会将表一行行读取并累加,类似与循环 ++
优化思路: 使用触发器在 insert 或者 delete 的时候 +1 或 -1 并存储在表中某一字段内即可。
count 的几种情况
-
count(*)InnoDB 引擎不会把字段全部取出而是专门做了优化,不取值直接在服务层按行进行类型。
-
count(1)我们所查询的每一条记录都会放一个 1 进去,然后在服务器层对数据进行累加 (如果是 1 就 +1)
-
count(主键)InnoDB 引擎会遍历整张表,然后把每一行的主键 id 值取出,返回给服务器层,服务器层拿到后直接开始累加 (因为主键不可能为 null)
-
count(字段)没有 not null 约束:innoDB 引擎会遍历整张表,然后把每一行的字段值取出返回给服务器层判断是否为 null
有 not null 的约束:InnoDB 引擎会遍历整张表,然后把每一行的字段值取出返回给服务器层直接开始累加
从上到下效率依次降低
七,Update优化(避免行锁升级为表锁)
在 InnoDB 引擎中开启事务后执行 update 语句他会将数据行锁住即行锁。
事务没提交前行锁不会释放,注意一定要对索引数据进行更新才能避免从行锁升级为表锁。
原因: 在 InnoDB 引擎中他不是针对记录加的行锁而是根据索引加的行锁,在更新数据的时候如果索引失效那么就会从行锁升级为表锁。