

一,概述
索引是帮助 MYSQL高效获取数据的有序数据结构
数据库维护着满足特定查找算法的数据结构,这种数据结构以某种方式指向数据。
这样就可以在数据结构上实现高级查找方法,这种数据结构就是索引。
- 无索引的时候查询数据会进行全表扫描操作
- 有索引的时候查询数据会进行排序二叉树的数据结构来查找数据
索引的优缺点:
- 优点:提高排序效率,检索效率。
- 缺点:降低插入,删除,更新的效率且索引本身占用空间。
二,索引的结构
索引是在存储引擎层实现,故不同的存储引擎有不同的索引结构。
2.1 分类
| 索引结构 | 描述 |
|---|---|
| B+Tree结构 | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash结构 | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询。 |
| R-tree结构(空间索引) | 空间索引是MyISAM引擎的一种特殊索引类型,主要用于地理空间数据描述,使用较少。 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。 |
2.2 支持情况
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |
2.3 索引相关数据结构
2.3.1 二叉树
顺序插入的时候,会形成一个链表,查询性能大大降低,大量数据的情况下,层次较深,检索速度慢,可以通过红黑树解决,但红黑树在大数据量的情况下,层次也较深,检索速度很慢
2.3.2 B-Tree(多路平衡查找树)
介绍:B 树是一种 自平衡的、多路搜索树,专门为需要高效读写大量数据的场景设计(如数据库、文件系统)。
核心特点
- 每个节点可以存储多个键(关键字),而不是像二叉树那样每个节点只能存一个键。
- 通过严格的平衡规则,确保所有叶子节点位于同一层,避免树的高度过高。
- 优化磁盘I/O:节点的大小通常设计为磁盘块的大小(如4KB),减少磁盘访问次数。
性质
- 一颗m阶的B树存放(m-1)个关键字,一个节点最多m个指针引用。
- 叶节点具有相同的深度,叶结点的指针为空
- 结点中的数据从左到右递增
- 当B-Tree作为索引元素时,所有的索引元素不可以重复
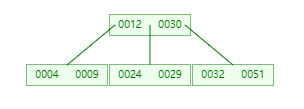
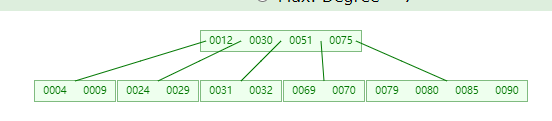
B 树形成流程简述
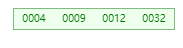
首先定义一个5 阶的 B 树 (平衡 5 路查找树), 现在我们要把
4、9、32、12、24、30、51、29、69、31、90、70、75、79、、80、85、91
-
根据 B 树的性质得 5 阶 B 树一个节点最多 4 个值,故取出 4 9 32 12 形成第一个节点并内部排序成 4 9 12 32
-
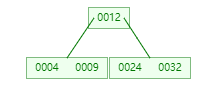
插入 24
-
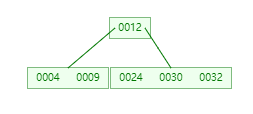
插入 30
-
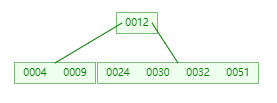
插入 51
-
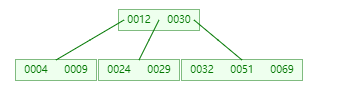
插入 29
-
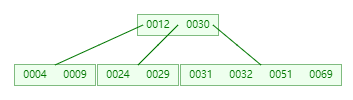
插入 69
-
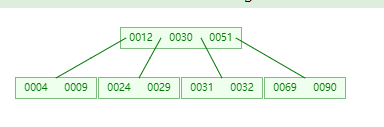
插入 31
-
插入 90
-
插入 70
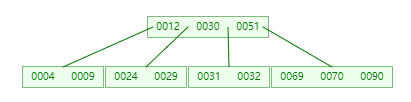
-
插入 75
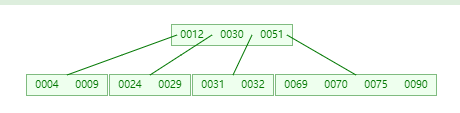
-
插入 79
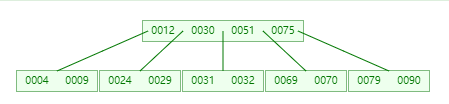
-
插入 80
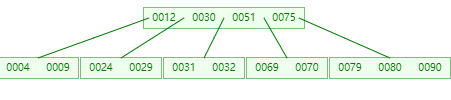
-
插入 85
-
插入 91
具体去看数据结构 B 树的组成会更方便理解。暂时只要了解 B 树的结构性质即可。
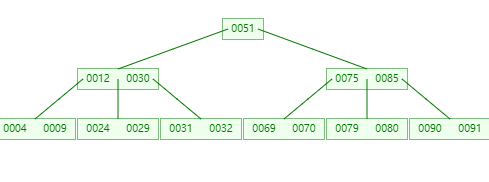
2.3.3 B+Tree
介绍:B+ 树 是一种自平衡的多路搜索树,是 B 树的扩展版本。它广泛应用于数据库和文件系统中,特别适合处理大量数据的 范围查询 和 顺序访问。
核心特点:
- 所有数据存储在叶子节点,内部节点仅作为索引(存放键值,不存储实际数据)。
- 叶子节点通过指针链接,形成有序链表,便于范围查询。
- 更高的扇出(Fan-out):内部节点可容纳更多子节点,减少树的高度和磁盘I/O次数。
首先定义一个5 阶的 B 树 (平衡 5 路查找树), 现在我们生成 B+ 树如图
4、9、32、12、24、30、51、29、69、31、90、70、75、79、、80、85、91
b+ 树相 vs b 树的区别:
| 特性 | B树 | B+树 |
|---|---|---|
| 数据存储位置 | 所有节点均可存储数据 | 仅叶子节点存储数据,内部节点仅索引 |
| 叶子节点链接 | 无 | 叶子节点通过指针链接成有序链表 |
| 查询效率稳定性 | 不稳定(可能在内部节点找到数据) | 稳定(必须访问叶子节点) |
| 范围查询性能 | 较差(需遍历树) | 极优(直接遍历叶子链表) |
| 内部节点结构 | 键值与数据共存 | 键值仅用于路由,不存储数据 |
| 空间利用率 | 较低(非叶子节点存储数据) | 较高(内部节点纯索引) |
2.3.4 Hash
特点
-
只能进行对比操作,即 = 和 in 这种精确的值,不支持范围查询。
-
无法利用索引进行排序。
-
查询效率很高,一般进行一次索引即可 (不出现 hash 冲突的情况下) 效率高于 B+ 树
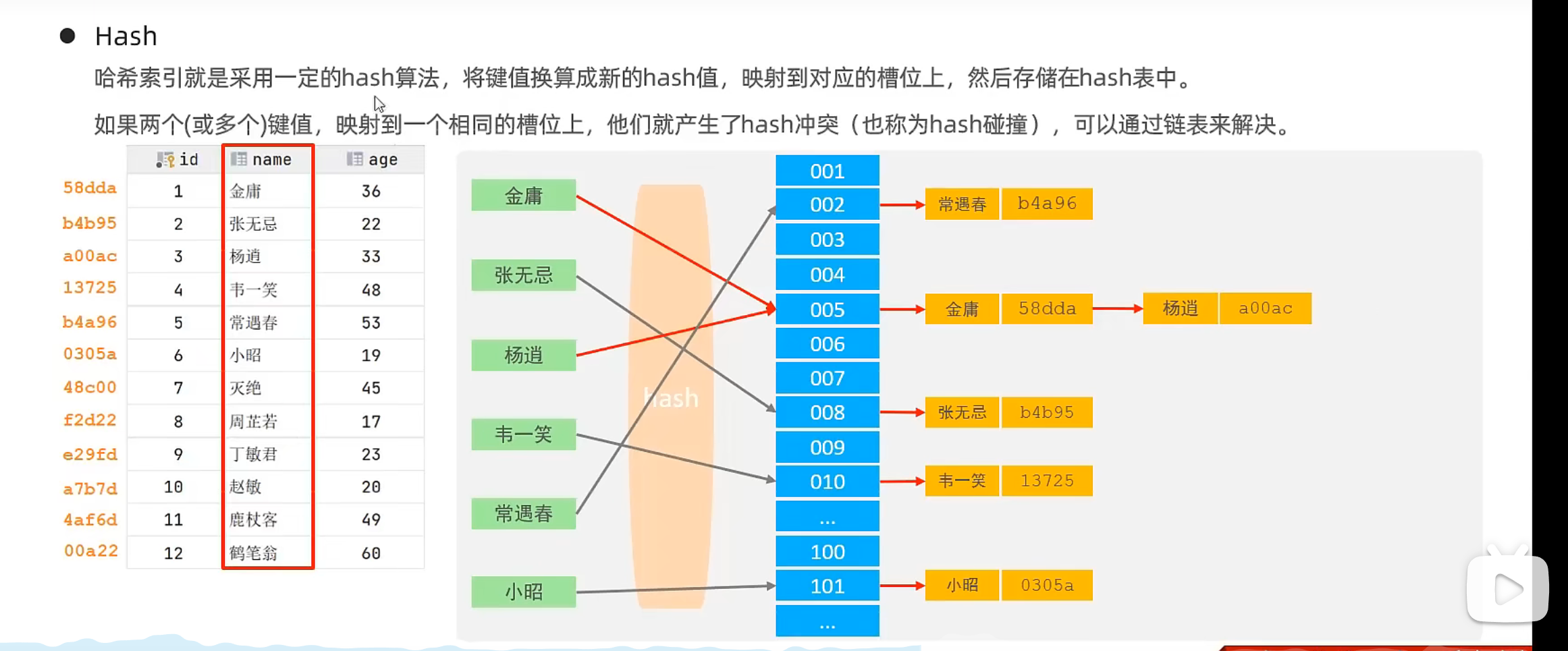
在 MYSQL 数据库中,Memory 引擎支持 hash 索引,但是在 innodb 引擎具有自适应 hash 功能
InnoDB 的 自适应哈希索引(Adaptive Hash Index,AHI) 是 InnoDB 引擎内部的一个优化机制,旨在针对特定查询场景加速等值查询(如
WHERE key = value)。其核心设计目标是 减少对 B+Tree 的频繁访问,尤其是在热点数据的查询场景中提升性能。简单来说就是对频繁的等值查询建立一个缓存
2.4 为什么InnoDB引擎选择使用B+tree索引结构
InnoDB 选择 B+Tree 作为索引结构,主要基于以下核心原因:
-
减少磁盘 I/O 次数,提升查询效率
-
B+Tree 的多叉结构:每个节点可以存储大量键值(
M叉,通常上千),使得树的高度较低(一般 3-4 层即可存储千万级数据)。树高越低,查询时需要的磁盘 I/O 次数越少。 -
对比 B-Tree:B-Tree 的节点存储数据本身,导致单个节点能容纳的键值更少,树高可能更高,I/O 次数更多。
-
对比二叉树:二叉平衡树(如红黑树)在存储海量数据时,树高会急剧增加(例如 1000 万数据需要约 24 层),导致 I/O 次数不可接受。
-
-
天然适合范围查询
-
叶子节点的链表结构:B+Tree 的所有数据存储在叶子节点,且叶子节点通过双向链表连接。范围查询(如
WHERE id BETWEEN 10 AND 100)只需遍历链表即可完成,无需回溯上层节点。 -
对比 B-Tree:B-Tree 的数据分布在所有节点,范围查询需要复杂的中序遍历,可能涉及多次非叶子节点的访问。
-
-
查询性能稳定
-
所有查询最终落到叶子节点:无论查询条件是主键、唯一索引还是普通索引,B+Tree 的查询路径长度相同(等于树高),时间复杂度稳定为
O(log N)。 -
对比 B-Tree:B-Tree 可能在非叶子节点直接命中数据,导致查询时间不稳定。
-
-
充分利用磁盘预读特性
-
局部性原理:磁盘按页(通常 4KB/16KB)读取数据,B+Tree 的节点大小设置为磁盘页的整数倍,单个节点可被一次性加载,减少 I/O 次数。
-
顺序访问优化:B+Tree 的叶子节点链表适合顺序扫描(如全表扫描或范围查询),而机械磁盘的顺序读取速度远高于随机读取。
-
-
支持聚簇索引与二级索引的统一结构
-
InnoDB 的聚簇索引:数据行直接存储在 B+Tree 的叶子节点中,主键索引即数据文件,避免二次查询。
-
二级索引(非聚簇索引):叶子节点存储主键值,通过回表查询获取完整数据,B+Tree 结构统一适配这种设计。
-
总结
InnoDB 选择 B+Tree 的核心原因是:在减少磁盘 I/O、高效支持范围查询、稳定查询性能之间实现了最佳平衡。这种设计完美契合了关系型数据库(尤其是 OLTP 场景)的典型负载,即大量基于索引的点查询、范围查询和排序操作。
三,索引的分类
3.1 按逻辑功能(用途)分类
- 主键索引(PRIMARY KEY)
- 特点:唯一标识每行数据,不允许重复和空值(
NULL),每个表只能有一个主键索引。 - 示例:
CREATE TABLE users (id INT PRIMARY KEY, ...);
- 特点:唯一标识每行数据,不允许重复和空值(
- 唯一索引(UNIQUE INDEX)
- 特点:确保列值的唯一性,允许空值(
NULL),但每个NULL视为唯一值(不同数据库实现可能不同)。 - 示例:
CREATE UNIQUE INDEX email_unique ON users(email);
- 特点:确保列值的唯一性,允许空值(
- 普通索引(INDEX)
- 特点:最基本的索引,无唯一性约束,仅加速查询。
- 示例:
CREATE INDEX idx_age ON users(age);
- 全文索引(FULLTEXT INDEX)
- 特点:针对文本内容(如文章、描述)的关键词搜索,支持自然语言检索。
- 引擎支持:MyISAM 默认支持,InnoDB 从5.6版本开始支持。
- 示例:
CREATE FULLTEXT INDEX content_idx ON articles(content);
- 组合索引(复合索引)
- 特点:将多个列组合成一个索引,遵循最左前缀原则(查询条件需包含最左列才能生效)。
- 示例:
CREATE INDEX idx_name_age ON users(name, age);- 有效查询:
WHERE name='Alice'或WHERE name='Alice' AND age=30 - 无效查询:
WHERE age=30(未使用最左列name)
- 有效查询:
3.2 按数据结构分类
- B+树索引
- 特点:MySQL默认的索引类型,支持范围查询(
>,<,BETWEEN)和排序,适用于等值查询和范围查询。 - 适用场景:大多数情况下的索引选择,如主键、唯一索引、普通索引均基于B+树。
- 特点:MySQL默认的索引类型,支持范围查询(
- 哈希索引
- 特点:基于哈希表实现,仅支持精确等值查询(
=),查询速度极快(O(1)),但不支持范围查询和排序。 - 引擎支持:Memory引擎默认支持,InnoDB支持自适应哈希索引(由引擎自动管理)。
- 示例:
CREATE INDEX idx_hash USING HASH ON users(email);
- 特点:基于哈希表实现,仅支持精确等值查询(
- 全文索引(倒排索引)
- 特点:通过分词构建倒排列表,实现关键词搜索。
- R-Tree索引(空间索引)
- 特点:用于地理空间数据(如经纬度),支持空间查询(
ST_Contains,ST_Distance)。 - 引擎支持:MyISAM和InnoDB(5.7+)。
- 示例:
CREATE SPATIAL INDEX location_idx ON places(coordinates);
- 特点:用于地理空间数据(如经纬度),支持空间查询(
3.3 按存储方式分类
- 聚蔟索引(Clustered Index)
- 特点:索引的叶子节点直接存储行数据,数据按索引顺序物理排序。
- 规则:
- 若表定义了主键,则主键为聚集索引。
- 若无主键,则选择第一个唯一非空索引。
- 若均无,InnoDB会生成隐藏的
ROW_ID作为聚集索引。
- 性能:数据查询快,但插入和更新可能需调整数据位置。
- 二级索引(Secondary Index)
- 特点:叶子节点存储主键值(非数据行),查询需回表(通过主键再到聚集索引获取数据)。
- 示例:普通索引、唯一索引、组合索引均为二级索引。
回表:指的是在使用 ** 二级索引(非聚集索引)查询数据时,需要根据索引中存储的主键值,回到聚集索引(主键索引)** 中再次查找完整数据行的过程。
回表的核心原理
- 索引结构差异:
- 聚蔟索引:叶子节点直接存储完整数据行(如
id是主键时,按id排序存储数据)。- 二级索引(如普通索引、唯一索引):叶子节点存储主键值,而非数据行。
- 查询流程:
- 步骤1:通过二级索引查找到目标记录对应的主键值。
- 步骤2:再通过主键值到聚集索引中查找完整数据行。
3.4 其他特殊类型
- 前缀索引
- 特点:对字段的前N个字符创建索引,节省空间,但可能降低区分度。
- 示例:
CREATE INDEX idx_prefix ON articles(title(10));(仅索引title的前10个字符)
- 自适应哈希索引(AHI)
- 特点:InnoDB自动为频繁访问的索引页创建哈希索引,用户无法手动创建。
四,索引的语法
创建索引
Create [unique|fulltext] index 索引名 on 表名(字段列表);
- unique代表唯一索引,字段列表中不能出现重复
- fulltext代表全文索引
- 如果这俩个都不加就默认创建常规索引
- 一个索引只关联一个字段的叫单列索引
- 一个索引关联多个字段的叫联合索引
- 只关联了主键的索引叫主键索引
查看索引
show index from 表名;
删除索引
Drop index 索引名 on 表名;
五,SQL性能分析
5.1 SQL执行效率
查看服务器状态信息
show [session|global] status;
5.1.1 常见状态变量及含义
| 变量名 | 说明 |
|---|---|
| Connections | 服务器启动以来总连接数(含成功和失败)。 |
| Threads_connected | 当前活跃连接数(即并发连接数)。 |
| Queries | 服务器启动以来执行的 SQL 语句总数(含 SELECT、UPDATE、DELETE 等)。 |
| Innodb_rows_read | InnoDB 引擎读取的行数。 |
| Innodb_rows_inserted | InnoDB 引擎插入的行数。 |
| Slow_queries | 执行时间超过 long_query_time 的慢查询数量。 |
| Select_scan | 全表扫描的 SELECT 查询次数(需优化索引)。 |
| Table_locks_waited | 表级锁等待次数(高值可能表示锁竞争)。 |
| Aborted_connects | 尝试连接到数据库但失败的次数(如密码错误)。 |
5.1.2 实际应用场景
场景 1:监控查询负载
SHOW GLOBAL STATUS LIKE 'Queries';
-
两次执行后计算差值,可得到 QPS(每秒查询量):
第一次值:Queries = 1000 第二次值(间隔1秒后):Queries = 1200 QPS = (1200 - 1000) / 1 = 200
场景 2:分析索引有效性
SHOW GLOBAL STATUS LIKE 'Handler_read%';
- Handler_read_first:索引首次被读的次数。
- Handler_read_next:索引顺序读的次数。
- Handler_read_prev:索引逆序读的次数。
- Handler_read_rnd:随机读的次数(高值可能表明缺少索引或全表扫描)。
场景 3:检测锁竞争
SHOW GLOBAL STATUS LIKE 'Table_locks_waited';
- 若该值持续增长,说明存在表级锁竞争,需优化事务或改用行级锁(InnoDB)。
5.2 慢日志查询
5.2.1 配置慢查询日志
慢查询日志是 MySQL 中用于记录执行时间超过指定阈值的 SQL 语句的核心工具,帮助开发者快速定位低效查询并进行优化。
- 慢查询日志记录了所有执行时间超过指定参数(默认10s)的所有SQL语句的日志,默认是关闭的。
查看当前配置
SHOW VARIABLES LIKE '%slow_query%';
-- 关键参数:
-- slow_query_log:是否开启(ON/OFF)
-- slow_query_log_file:日志文件路径
-- long_query_time:慢查询阈值(秒)
-- log_queries_not_using_indexes:是否记录未使用索引的查询(ON/OFF)
动态开启(无需重启 MySQL)
-- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
-- 设置阈值(如2秒)
SET GLOBAL long_query_time = 2;
-- 记录未使用索引的查询(即使执行时间未超阈值)
SET GLOBAL log_queries_not_using_indexes = 'ON';
永久配置(修改 my.cnf/my.ini)
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/lib/mysql/mysql-slow.log
long_query_time = 2
log_queries_not_using_indexes = 1
重启 MySQL 生效:
systemctl restart mysqld
5.2.2 慢查询日志格式解析
一条典型的慢查询日志记录如下:
# Time: 2023-10-05T14:23:45.123456Z
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 5.123456 Lock_time: 0.001234 Rows_sent: 10 Rows_examined: 100000
SET timestamp=1696515825;
SELECT * FROM orders WHERE status = 'pending' ORDER BY create_time DESC;
- Query_time:SQL 执行时间(单位:秒)。
- Lock_time:等待锁的时间。
- Rows_sent:返回给客户端的行数。
- Rows_examined:扫描的行数(值越大,越可能缺少索引)。
- SQL 语句:记录的完整查询内容。
5.2.3 分析慢查询日志的工具
mysqldumpslow(MySQL 自带)
# 按执行时间排序统计前10条慢查询
mysqldumpslow -s t -t 10 /var/lib/mysql/mysql-slow.log
# 按出现次数排序
mysqldumpslow -s c -t 10 /var/lib/mysql/mysql-slow.log
# 输出示例
Count: 5 Time=4.12s (20s) Lock=0.00s (0s) Rows=10.0 (50), root[root]@localhost
SELECT * FROM users WHERE age > N
pt-query-digest(Percona Toolkit)
更强大的第三方工具,支持生成详细报告:
# 分析日志并输出报告
pt-query-digest /var/lib/mysql/mysql-slow.log > slow_report.txt
# 输出内容示例
# 1. 总体统计:总查询数、唯一 SQL 指纹、时间分布
# 2. 单个 SQL 分析:执行次数、平均/最大耗时、扫描行数、索引建议
5.3 Profiles
Profiling 是 MySQL 中用于分析单条 SQL 语句执行细节的工具,能够展示查询过程中各阶段的耗时,帮助开发者定位性能瓶颈
Profiles 作用
- 逐阶段耗时分析:分解 SQL 执行流程(如语法解析、优化、锁等待、数据传输等),显示每个步骤的耗时。
- 精准定位瓶颈:识别慢查询的具体阶段(如
Sending data或System lock)。 - 对比优化效果:在修改 SQL 或索引后,重新 Profiling 验证优化效果。
5.3.1 启用 Profiling
1. 开启 Profiling 功能
-- 开启会话级别的 Profiling(仅对当前连接有效)
SET SESSION profiling = 1;
-- 查看是否启用成功(Value 应为 ON)
SHOW VARIABLES LIKE 'profiling';
2. 执行待分析的 SQL
-- 示例:分析一个复杂查询
SELECT * FROM orders
WHERE user_id IN (SELECT id FROM users WHERE age > 30)
ORDER BY create_time DESC LIMIT 100;
3. 查看 Profiling 结果
-- 列出所有已记录的查询及其 Query_ID
SHOW PROFILES;
-- 查看某条查询的详细耗时(替换[QUERY_ID])
SHOW PROFILE FOR QUERY [QUERY_ID];
5.3.2 Profiling 输出解读
执行 SHOW PROFILE FOR QUERY 1; 示例输出:
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000065 |
| checking permissions | 0.000010 |
| Opening tables | 0.000023 |
| init | 0.000045 |
| System lock | 0.000018 |
| optimizing | 0.000016 |
| statistics | 0.000025 |
| preparing | 0.000020 |
| executing | 0.000006 |
| Sending data | 0.123456 | -- 主要耗时阶段
| end | 0.000012 |
| query end | 0.000009 |
| closing tables | 0.000011 |
| freeing items | 0.000020 |
| cleaning up | 0.000015 |
+----------------------+----------+
关键状态说明
| 状态 | 说明 |
|---|---|
| Sending data | 从存储引擎读取数据并发送到客户端(常见瓶颈,可能涉及全表扫描或回表)。 |
| System lock | 等待表锁或行锁(高并发场景下需优化事务或索引减少锁冲突)。 |
| Sorting result | 对结果排序(无索引排序时可能消耗大量内存和 CPU)。 |
| Creating tmp table | 创建临时表(常见于 GROUP BY、子查询,需优化 SQL 或增加内存配置)。 |
5.4 Explain执行计划
EXPLAIN 是 MySQL 中分析 SQL 语句执行计划的核心工具,通过解析查询优化器选择的执行路径,帮助开发者判断索引使用情况、表关联顺序及潜在性能瓶颈。
5.4.1 EXPLAIN 基础语法
EXPLAIN [FORMAT=JSON] SELECT ...;
- 默认格式:表格形式展示执行计划(常用)。
- JSON 格式:更详细信息,适合程序解析(如
EXPLAIN FORMAT=JSON SELECT ...)。
5.4.2 EXPLAIN 输出字段解析
| 字段 | 说明 | 优化关注点 |
|---|---|---|
| id | 查询序号(层级)。id 相同表示同级执行,id 越大优先级越高(如子查询)。 | 子查询优化、嵌套逻辑。 |
| select_type | 查询类型。 | 简单查询、子查询、UNION 等场景区分。 |
| table | 访问的表名(或别名)。 | 确认实际访问的表,尤其是多表 JOIN 场景。 |
| partitions | 匹配的分区(仅当表分区时有效)。 | 分区裁剪是否生效。 |
| type | 访问类型(关键指标)。从最优到最差排序:system > const > eq_ref > ref > range > index > ALL。 | 避免 ALL(全表扫描),优先优化为 ref 或 range。 |
| possible_keys | 可能使用的索引列表。 | 检查是否遗漏预期索引。 |
| key | 实际选择的索引。 | 是否命中高效索引,避免 NULL(未用索引)。 |
| key_len | 索引使用的字节数。 | 判断索引是否充分利用(如组合索引的前缀长度)。 |
| ref | 索引关联的列或常量。 | 确认索引匹配的字段(如 const 或 table.column)。 |
| rows | 预估扫描的行数(关键指标)。 | 值越小越好,高值可能需优化索引或查询条件。 |
| filtered | 存储引擎返回数据后,经过 WHERE 条件过滤的剩余行百分比(0~100)。 | 低百分比表示 WHERE 过滤效率低,可能需优化条件或索引。 |
| Extra | 附加信息(关键指标)。常见值:Using index、Using temporary、Using filesort 等。 | 避免 Using filesort 和 Using temporary,优先优化排序和分组逻辑。 |
5.4.3 核心字段详解与优化方向
1. type(访问类型)
- system:表仅有一行数据(系统表)。
- const:通过主键或唯一索引查找,最多返回一行(如
WHERE id=1)。 - eq_ref:JOIN 时使用主键或唯一索引关联(如
A JOIN B ON A.id=B.id)。 - ref:非唯一索引查找(如
WHERE name='Alice')。 - range:索引范围扫描(如
WHERE age > 20)。 - index:全索引扫描(遍历索引树)。
- ALL:全表扫描(需紧急优化)。
优化建议:
- 确保 WHERE 条件列有索引,避免
ALL。 - 使用组合索引时遵循最左前缀原则。
2. Extra(附加信息)
- Using index:覆盖索引(无需回表)。
- Using where:存储引擎返回数据后,在 Server 层再次过滤。
- Using temporary:使用临时表(常见于 GROUP BY、DISTINCT 未用索引)。
- Using filesort:文件排序(内存或磁盘排序,需优化 ORDER BY)。
- Using join buffer:使用 JOIN 缓冲区(增大
join_buffer_size或优化 JOIN 条件)。
优化建议:
- 为 GROUP BY 和 ORDER BY 字段添加索引,消除临时表和文件排序。
- 减少 SELECT *,使用覆盖索引。
3. select_type(查询类型)
- SIMPLE:简单查询(无子查询或 UNION)。
- PRIMARY:外层查询(包含子查询时)。
- SUBQUERY:子查询中的第一个 SELECT。
- DERIVED:派生表(FROM 子句中的子查询)。
- UNION:UNION 中的第二个或后续查询。
- UNION RESULT:UNION 的结果集。
优化建议:
- 将复杂子查询改写为 JOIN。
- 避免多层派生表(DERIVED),改用临时表或优化查询结构。
5.4.4 EXPLAIN 优化流程图
- 检查 type 字段:
- 若为
ALL→ 添加 WHERE 条件索引。 - 若为
index→ 检查是否可优化为范围扫描。
- 若为
- 分析 Extra 字段:
Using filesort→ 为 ORDER BY 添加索引。Using temporary→ 优化 GROUP BY 或使用覆盖索引。
- 预估 rows 值:
- 高 rows 值 → 检查索引选择性或优化查询条件。
- 验证 key 选择:
- 未使用预期索引 → 强制索引(
USE INDEX)或优化索引结构。
- 未使用预期索引 → 强制索引(
六,使用索引的规则
6.1 联合索引
-
索引结构
-
数据组织方式:联合索引按字段顺序构建 B+ 树。
例如,索引(col1, col2, col3)的键值按col1→col2→col3排序存储。实际上默认还加了一个主键字段 (主键,col1,col2,col3)
- 排序规则:先按
col1排序,col1相同则按col2排序,依此类推。
- 排序规则:先按
-
-
最左前缀原则(Leftmost Prefix Principle)
联合索引
(col1, col2, col3)可支持以下查询:WHERE col1 = ? -- ✅ 使用索引 WHERE col1 = ? AND col2 = ? -- ✅ 使用索引 WHERE col1 = ? AND col2 = ? AND col3 = ? -- ✅ 使用索引但以下查询无法使用该索引:
WHERE col2 = ? -- ❌ 未包含最左列 col1 WHERE col1 = ? AND col3 = ? -- ❌ 跳过中间列 col2 -
与单列索引的区别
联合索引 != 创建多个索引
-
覆盖性:联合索引支持前缀组合的查询,但无法替代所有单列索引。
例如,索引(col1, col2)能加速col1或col1+col2的查询,但无法加速单独查col2。 -
索引数量:联合索引本质是单个索引,并非真正创建多个独立索引。
-
6.2 最左匹配规则的底层原理
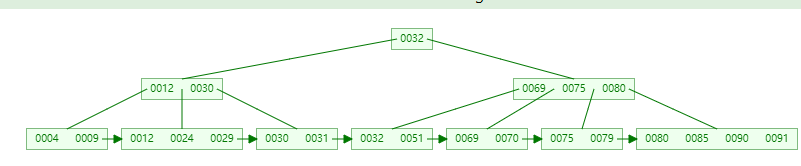
索引的底层是一颗 B+ 树,联合索引底层当然也是一颗 B+ 树,区别在于联合索引的键值是多个,但是构建一颗 B+ 树只能根据一个值来构建,故数据库依据联合索引最左字段来构建 B+ 树!
假定创建一个 (a,b,c) 的联合索引,索引树如图
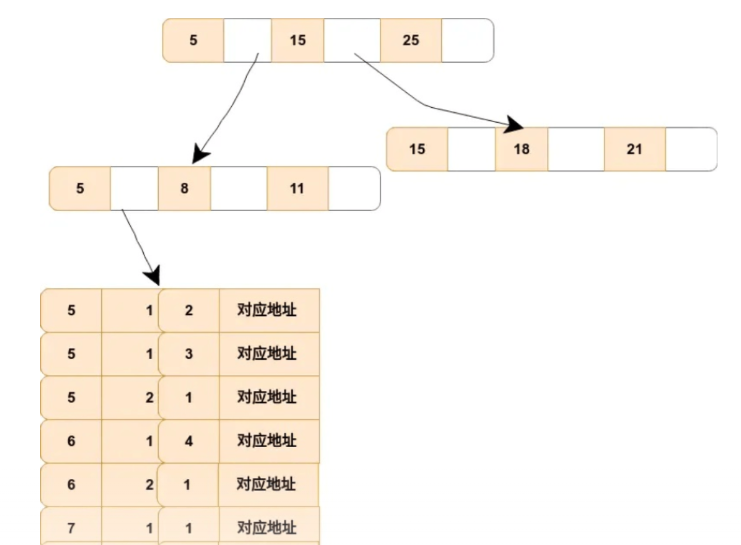
该图就是通过 (a,b,c) 联合索引形成的 B+ 树,可以看出非叶子节点存储的是第一个关键字的所有 a,叶子节点存储的是三个关键字的数据。
可以看出 a 是有序的 b,c 是无序的,当 a 相同时 b 是有序的,b 相同时又是有序的,这就是最左匹配规则的底层原理!
联合索引就是按照第一列进行排序,然后第一列排好序的基础上再对第二列进行排序,以此类推。如果没有第一列直接访问第二列,第二列肯定是无序的,直接访问后面的列就用不到索引了。
6.3 查询优化器
MySQL 查询优化器是 SQL 执行前的核心模块,负责将用户的 SQL 语句转化为高效执行计划。其目标是以最小的资源消耗(CPU、I/O、内存)获取正确结果。
问:如果举例索引顺序为 (a,b,c) 但查询条件为 where b=1 and a = 2; 为什么还用到了索引
答:理论上索引对顺序是敏感的,但是由于 MySQL 的查询优化器会自动调整 where 子句的条件顺序以使用适合的索引,所以 MySQL 不存在 where 子句的顺序问题而造成索引失效。
6.4 索引失效的几种情况与解决方法
6.4.1 在索引列上使用函数或表达式
场景:
-- 索引列使用函数
SELECT * FROM users WHERE YEAR(create_time) = 2023;
-- 索引列参与运算
SELECT * FROM users WHERE age + 1 > 30;
原因: 索引存储的是原始值,而非计算后的结果,优化器无法直接匹配索引树。
解决:
- 改写 SQL,保持索引列原始值:
SELECT * FROM users WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31'; SELECT * FROM users WHERE age > 29; -- age > (30 - 1) - MySQL 8.0+ 函数索引(直接索引计算后的值):
CREATE INDEX idx_year ON users( (YEAR(create_time)) );
6.4.2 违反最左前缀原则(联合索引)
场景:联合索引 (a, b, c),但查询条件未包含最左列:
SELECT * FROM table WHERE b = 2 AND c = 3;
原因:
联合索引按 a → b → c 顺序构建,跳过最左列时无法利用索引。
解决:
- 调整查询条件,包含最左列:
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3; - 重建联合索引顺序(根据高频查询场景调整字段顺序)。
6.4.3 隐式类型转换
场景:
字段为字符串类型,但查询时使用数值:
-- 假设 phone 是 VARCHAR 类型
SELECT * FROM users WHERE phone = 13800138000;
原因: MySQL 会将字符串字段隐式转换为数值,导致索引失效。
解决:
-
保持类型一致:
SELECT * FROM users WHERE phone = '13800138000';
6.4.4 使用 OR 连接非索引字段
场景:
-- 索引为 (age)
SELECT * FROM users WHERE age = 25 OR name = 'Alice';
原因: 若 OR 两侧字段不全是索引列,优化器会选择全表扫描。
解决:
- 使用
UNION替代OR:SELECT * FROM users WHERE age = 25 UNION SELECT * FROM users WHERE name = 'Alice'; - 为
name字段单独建索引:CREATE INDEX idx_name ON users(name);
6.4.5 模糊查询以通配符开头
场景:
-- 索引为 (title)
SELECT * FROM articles WHERE title LIKE '%MySQL%';
原因: 前导通配符 % 导致无法利用索引顺序扫描。
解决:
-
使用前缀匹配(仅支持
LIKE 'MySQL%'):SELECT * FROM articles WHERE title LIKE 'MySQL%'; -
全文索引(针对大文本搜索):
CREATE FULLTEXT INDEX ft_content ON articles(title); SELECT * FROM articles WHERE MATCH(title) AGAINST('MySQL');
6.4.6 范围查询后使用联合索引列
场景:联合索引 (a, b, c),但范围查询中断后续列:
SELECT * FROM table WHERE a = 1 AND b > 10 AND c = 2;
原因: 范围查询 b > 10 后,c 无法利用索引过滤。
解决:
-
调整索引顺序(将等值列放在范围列前):
CREATE INDEX idx_a_c_b ON table(a, c, b);
6.4.7 索引选择性过低
场景:
在性别(gender)字段上建索引:
SELECT * FROM users WHERE gender = 'Female';
原因: 性别只有少数枚举值(如 Male/Female),索引区分度低,优化器认为全表扫描更快。
解决:
- 避免对低区分度字段建索引,或结合其他字段建组合索引:
CREATE INDEX idx_gender_age ON users(gender, age);
6.4.8 使用 != 或 NOT 操作符
场景:
-- 索引为 (status)
SELECT * FROM orders WHERE status != 'paid';
原因: 非等值查询需要扫描大部分索引树,优化器可能选择全表扫描。
解决:
- 改写为范围查询(需结合业务逻辑):
SELECT * FROM orders WHERE status IN ('unpaid', 'pending');
6.4.9 全表扫描更快时
场景:当表中数据量极小时,优化器认为全表扫描成本低于索引扫描。
解决:
- 无需优化:此为优化器合理决策,无需干预。
6.4.10 未触发索引覆盖(回表开销大)
场景:
-- 索引为 (age)
SELECT name, email FROM users WHERE age > 25;
原因: 索引未包含 name 和 email,需回表查询。
解决:
- 使用覆盖索引:
CREATE INDEX idx_age_name_email ON users(age, name, email);
总结:索引失效场景速查表
| 场景 | 解决方法 |
|---|---|
| 函数或表达式 | 避免对索引列计算,或使用函数索引(MySQL 8.0+) |
| 违反最左前缀原则 | 调整查询条件或索引顺序 |
| 隐式类型转换 | 保持字段与查询值类型一致 |
OR 连接非索引字段 | 改用 UNION 或为字段建索引 |
| 前导模糊查询 | 使用前缀匹配或全文索引 |
| 范围查询中断联合索引 | 调整索引顺序,优先等值列 |
| 低选择性索引 | 结合高区分度字段建组合索引 |
!= 或 NOT | 改写为 IN 或范围查询 |
| 覆盖索引未命中 | 创建覆盖索引,包含查询所有字段 |
通过合理设计索引和 SQL 语句,可有效避免索引失效,提升查询性能。建议结合 EXPLAIN 工具分析执行计划,验证优化效果。
6.5 SQL提示
就是 explain 字段中的 possible_key, 就 MYSQL提示我们使用的索引
假定有多个索引,而 MYSQL 会自动选择其中一个他认为比较好的索引,但有时另外一个索引更好。这个时候我们就使用 SQL 提示来解决。
建议数据库使用指定索引
select * from 表名 use index(索引名) where 条件;
告诉数据库不要用指定索引
select * from 表名 ignore index(索引名) where 条件;
强制数据库使用指定索引
select * from 表名 force index(索引名) where 条件;
6.6 覆盖索引
创建一个索引,该索引包含查询中用到的所有字段,称为“覆盖索引”。使用覆盖索引,MySQL 只需要通过索引就可以查找和返回查询所需要的数据,而不必在使用索引处理数据之后再进行回表操作,覆盖索引可以一次性完成查询工作,有效减少 IO,提高查询效率。
简单来的说,就是让查询的字段(包括 where 子句中的字段),都是索引字段
select a,b,c from 表名 where a=条件 and b=条件 and c=条件;
使用联合索引 (a,b,c) 即可实现覆盖索引。
6.7 前缀索引
当字段类型为 (varchar,char) 的时候,有时候需要索引很长的字符串,这样会占用大量空间,查询时候浪费大量磁盘 IO,非常影响效率。
解决办法:将字符串的一部分前缀建立索引即可。
建立前缀索引
Create index 索引名 on 表名(字段(n));
-
前缀长度:根据索引选择性决定,索引的选择性越高,查询效率就越高。
- 唯一索引的选择性为1,这时最好的索引选择性,性能最高。
-
选择性:索引值中不重复的部分,和数据中记录总数的比值。
-
选择性换算公式:
select count( distinct substring(字段名,1,n) ) / count(*) from 表名;n 表示前几个字符,自己随机选,求出最好的选择性即可.
6.8 索引下推
索引下推(Index Condition Pushdown,简称 ICP)是数据库优化查询性能的一种技术,主要用于减少存储引擎与服务器层之间的数据传输量,从而提升查询效率。
- 基本思想:将部分
WHERE条件的过滤操作从服务器层“下推”到存储引擎层,直接在遍历索引时进行过滤,减少不必要的回表操作。 - 适用场景:当查询条件包含索引列和非索引列时,ICP 允许在索引层过滤掉不符合条件的记录,仅回表查询剩余记录。
- 优势:减少回表次数(减少 I/O 和 CPU 开销),尤其对联合索引和范围查询效果显著。
场景
假设有一个图书借阅记录表,结构如下:
CREATE TABLE book_borrow (
id INT PRIMARY KEY,
book_name VARCHAR(100), -- 书名
borrow_date DATE, -- 借阅日期
user_id INT -- 用户ID
);
- 索引:在
(borrow_date, user_id)上建了一个联合索引。 - 需求:查询“2023年10月1日之后借阅,且用户ID是100的用户”的记录。
查询语句:
SELECT * FROM book_borrow
WHERE borrow_date > '2023-10-01'
AND user_id = 100;
无索引下推(传统方式)
-
存储引擎层:
- 使用索引
(borrow_date, user_id)找到所有borrow_date > '2023-10-01'的记录。 - 因为索引是联合索引,
borrow_date是第一列,可以快速定位到所有符合条件的日期。 - 但是:
user_id = 100是索引的第二列,此时存储引擎不会主动过滤user_id,而是将所有borrow_date > '2023-10-01'的记录全部返回给服务器层(即使user_id不是100)。
- 使用索引
-
服务器层:
- 接收所有
borrow_date > '2023-10-01'的记录。 - 再根据
user_id = 100进行过滤,最终得到结果。
- 接收所有
问题:存储引擎返回了大量 borrow_date > '2023-10-01' 但 user_id ≠ 100 的无效记录,导致回表次数多、数据传输量大。
有索引下推(ICP 优化后)
-
存储引擎层:
- 使用索引
(borrow_date, user_id)找到所有borrow_date > '2023-10-01'的记录。 - 直接在索引层检查
user_id = 100(因为user_id是索引的第二列,可以直接在索引中获取到它的值)。 - 只将满足
borrow_date > '2023-10-01'且user_id = 100的记录回表查询完整数据。
- 使用索引
-
服务器层:
- 接收的已经是过滤后的记录(
borrow_date > '2023-10-01'且user_id = 100)。 - 直接返回结果,无需二次过滤。
- 接收的已经是过滤后的记录(
优势:存储引擎在扫描索引时,直接过滤了 user_id = 100,回表次数大幅减少。
关键点总结
-
索引下推的触发条件:
- 查询条件中的字段必须包含在索引中(比如
borrow_date和user_id都在索引里)。 - 即使某个条件不能直接用索引加速(比如
user_id = 100是联合索引的第二列),ICP 也能在索引层过滤它。
- 查询条件中的字段必须包含在索引中(比如
-
为什么说它“下推”了?
- 原本由服务器层做的过滤(
user_id = 100),现在“下推”到存储引擎层,直接在遍历索引时完成。
- 原本由服务器层做的过滤(
-
效果对比:
- 无 ICP:存储引擎返回 1000 条
borrow_date > '2023-10-01'的记录,其中只有 10 条是user_id = 100,需要回表 1000 次。 - 有 ICP:存储引擎直接过滤出 10 条
user_id = 100的记录,仅回表 10 次。
- 无 ICP:存储引擎返回 1000 条
再举个生活化的比喻
假设你是一个图书管理员:
- 无 ICP:你先把所有“2023年10月1日之后借阅”的书单(1000本)全部抄下来,再一本本检查用户ID是不是100,最后找到10本。
- 有 ICP:你抄书单时,直接边抄边核对用户ID,只抄下用户ID是100的10本书,省去了后续检查的步骤。
如何验证是否用了索引下推?
在 MySQL 中执行:
EXPLAIN SELECT * FROM book_borrow
WHERE borrow_date > '2023-10-01'
AND user_id = 100;
如果执行计划的 Extra 列显示 Using index condition,说明索引下推生效
七,索引的设计原则
MySQL 的 InnoDB 存储引擎中,主键(PRIMARY KEY)默认会自动创建一个聚集索引(Clustered Index),你不需要手动为它额外添加索引。这是 InnoDB 引擎的核心设计之一,目的是优化数据的存储和检索效率。
- 针对数据量大的,查询频繁的表建立索引。
- 针对常作为,where,order by,group by的条件的字段建立索引。
- 尽量选择区分度高的建立索引,区分度越高效率越高。
- 尽量建立唯一索引。
- 尽量使用联合索引,减少单列索引,查询的时候尽量使用覆盖所有,减少回表查询,从而提高销量。
- 控制索引的数量,索引越多维护的代价就越大,且影响增删改的效率,占用磁盘空间。
- 如果是字符串类型索引,且字符串较长,尽量使用前缀索引。
- 如果所有列不能存储null值,创建表的时候使用not null约束,让查询优化器找到每列是否包含null值,从而更好的选择用哪个索引查询。