

一、Kafka介绍
Kafka 是 Apache 开源的一款基于 zookeeper 协调的分布式消息系统,具有高吞吐率、高性能、实时、高可靠等特点,可实时处理流式数据。它最初由 LinkedIn 公司开发,使用 Scala 语言编写。
Kafka历经数年的发展,从最初纯粹的消息引擎,到近几年开始在流处理平台生态圈发力,多个组织或公司发布了各种不同特性的产品。常见产品如下:
- Apache Kafka :最“正统”的
Kafka也是开源版,它是后面其他所有发行版的基础。 - Cloudera/Hortonworks Kafka :集成了目前主流的大数据框架,能够帮助用户实现从分布式存储、集群调度、流处理到机器学习、实时数据库等全方位的数据处理。
- Confluent Kafka :主要提供基于
Kafka的企业级流处理解决方案。
Kafka 不是传统意义上的“消息队列”,它更准确是:
分布式日志系统(Distributed Log System) + 流处理平台
Kafka 的特点
- 高吞吐量、低延迟:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息,它的延迟最低只有几毫秒
- 持久性:支持消息持久化,即使数TB级别的消息也能够保持长时间的稳定性能。
- 可靠性:支持数据备份防止丢失
- 容错性:支持通过Kafka服务器和消费机集群来分区消息,允许集群中的节点失败(若分区副本数量为n,则允许n-1个节点失败)
- 高并发:单机可支持数千个客户端同时读写,支持在线水平扩展。可无缝对接hadoop、strom、spark等,支持Hadoop并行数据加载
Kafka 应用场景
| ID | 设计目标 | 功能 |
|---|---|---|
| 1 | 日志收集 | 一个公司用Kafka可以收集各种服务的Log,通过Kafka以统一接口服务的方式开放给各种Consumer |
| 2 | 消息系统 | 解耦生产者和消费者、缓存消息等 |
| 3 | 用户活动跟踪 | 用来记录Web用户或者APP用户的各种活动,如网页搜索、搜索、点击,用户数据收集然后进行用户行为分析。 |
| 4 | 运营指标 | Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告 |
| 5 | 流式处理 | 比如Spark Streaming和Storm |
核心思想 :消息不是“消费即删除”(RabbitMQ 思维)而是:消息被持久化存储,消费者自己决定读到哪(offset)
二,Kafka结构
2.1 Producer
负责:发送消息到 Kafka
关键点:可以指定 partition,默认根据 key hash 分区
2.2 Consumer
负责:从 Kafka 读取消息
重要特点:
- 主动拉取(pull)
- 自己维护 offset
2.3 Broker
一个 Kafka 服务器实例,在 Kafka 集群中会有多个 broker 实例
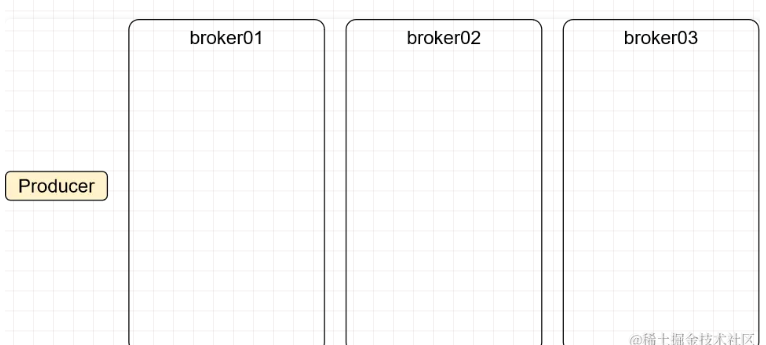
2.4 Topic
Topic 中文意思是主题,在 Kafka 中只是一个逻辑概念,代表某一类消息,结合具体项目中的业务功能,我们可以为每一个具体功能创建一个 Topic。
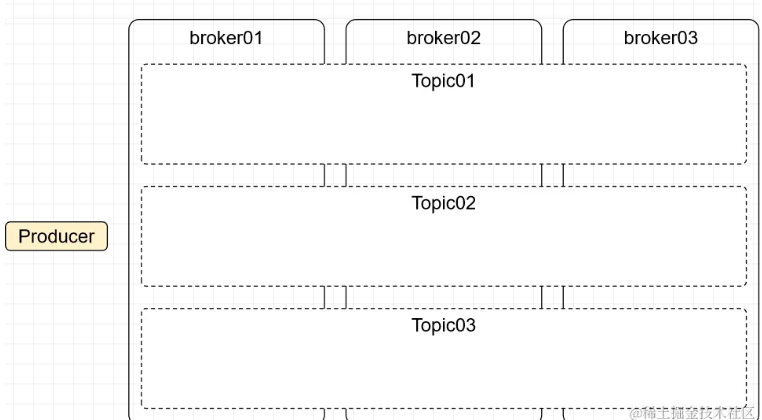
2.5 Partition
Partition 就是分区,为什么要分区?
- 有了分区就可以把消息数据分散到不同broker上保存。
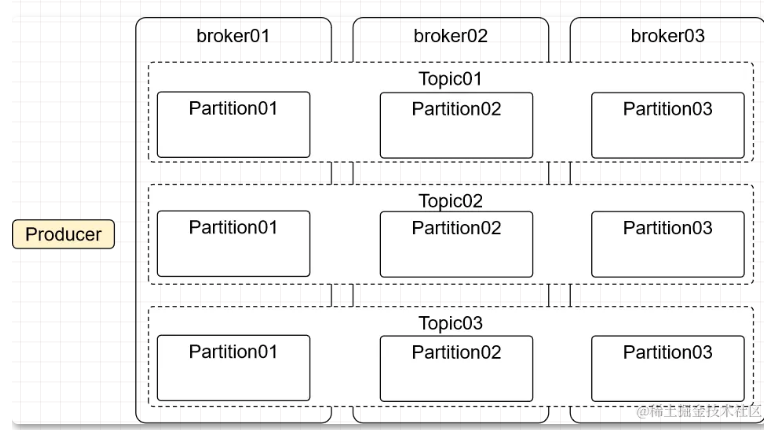
假设你有 3 个 broker(3 台机器):
| 分区数 | 含义 | 是否可行 |
|---|---|---|
| 1 个分区 | 所有数据只存在某一台 broker 上 | ✅ 可行 |
| 3 个分区 | 每台 broker 上存一个分区 | ✅ 可行 |
| 6 个分区 | 平均每台 broker 存 2 个分区 | ✅ 可行 |
| 10 个分区 | 有的 broker 存 3 个,有的存 4 个 | ✅ 可行 |
结论:分区数可以和 broker 数任意搭配, 分区越多 = 并行度越高 = 吞吐量越大(但有边际递减)
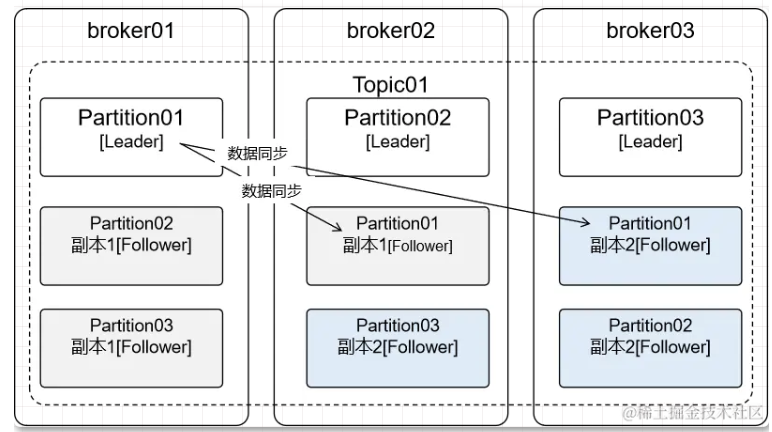
2.6 Replication
数据分区之后有一个问题:每个 broker 上保存一部分数据,如果某个 broker 宕机,那么数据就会不完整,所以 Kafka 允许分区创建副本。
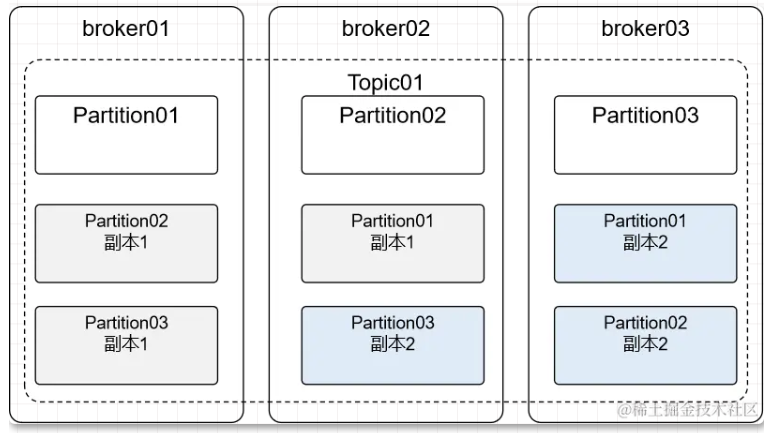
副本数必须 <=broker 数量
2.7 主从
当分区存在副本时,就会区分 Leader、Follower:
- Leader:主分片,负责接收生产者端发送过来的消息,对接消费者端消费消息
- Follower:不和生产者、消费者交互,仅负责和Leader同步数据
创建 Topic 时通过“分区数”指定 Partition 的数量,通过“复制因子”指定副本数量,分区数和复制因子都不能为 0
- 分区数为1,复制因子为1表示:1个Partition内有1个Leader(此时数据只有一份,没有冗余的副本,生产环境不建议)
- 复制因子为2表示每个Partition中包含1个Leader和1个Follower
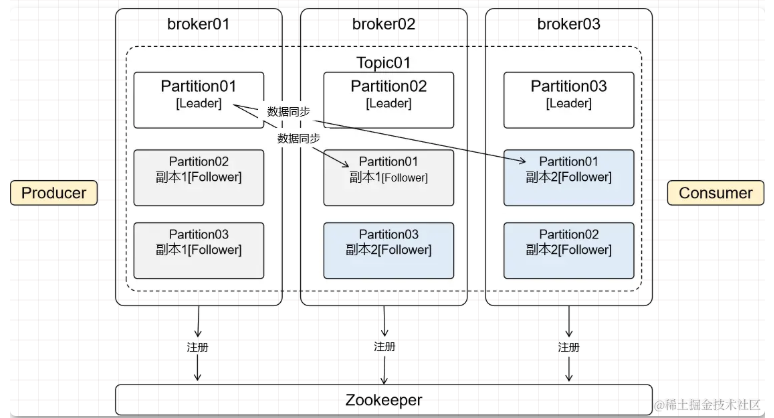
2.8 注册
Kafka 工作过程中,broker、Partition……信息都需要在 Zookeeper 中注册
二,Kafka vs RabbitMQ
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 模型 | 日志流 | 消息队列 |
| 消息删除 | 不删除(按时间/大小) | 消费即删 |
| 消费方式 | pull | push |
| 顺序性 | partition 内保证 | queue 保证 |
| 吞吐量 | 极高(百万级) | 较低 |
| 使用场景 | 日志、流处理、大数据 | 业务解耦、任务队列 |
结论:
- RabbitMQ:业务消息
- Kafka:数据流/日志流
三,Kafka的集群工作机制
Kafka 集群架构大体如下图:
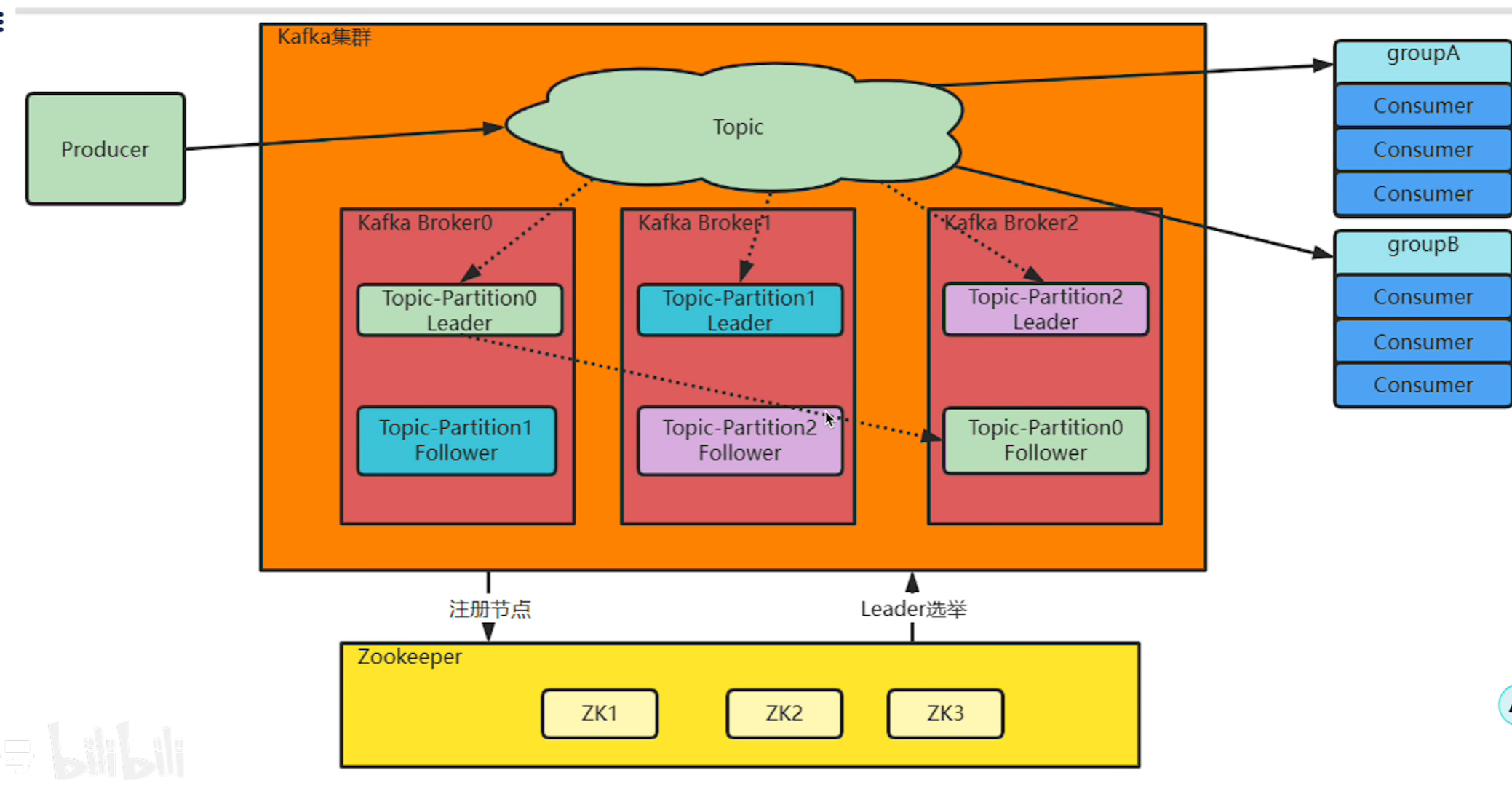
为什么要用集群?
单机服务下,Kafka 已经具备了非常高的性能。TPS 能够达到百万级别。但是,在际工作中使用时,单机搭建的 Kafka 会有很大的局限性。
-
一方面:消息太多,需要分开保存。Kafka 是面向海量消息设计的,一个 Topic 下的消息会非常多,单机服务很难存得下来。这些消息就需要分成不同的 Partition,分布到多个不同的 Broker 上。这样每个 Broker 就只需要保存一部分数据。这些分区的个数就称为分区数
-
另一方面:服务不稳定,数据容易丢失。单机服务下,如果服务崩溃,数据就丢失了,为了保证数据安全,就需要给每个 Partation 配置一个或多个备份,保证致据不丢失,Kafka 的集群模式下,每个 Partion 都有一个或多个备份。Kafka 会通过一个统一的 Zookeeper 集群作为选举中心,给每个 Partion 选举出一个主节点 Leader,其他节点就是从节点 Folower。主节点負责响应客户端的具体业务请求,并保存消息。而从节点则负责同步主节点的数据。当主节点发生故障时,Kaftka 会选举出一个从节点成为新的主节点。
-
最后:Kaka 集群中的这些 Broker 信息,包括 Partition 的选举信息,都会保存在额外部署的 Zookeper 集群当中,这样,kafka 集群就不会因为某一些 Broker 服务崩遗而中断。